

GPT로 데이터 분석을 하면 정말 편리하죠.
대화창에 엑셀 파일 올리고 온갖 분석도 하고 여러가지 그래프도 다 그려버리죠.
이 코드를 구글 코랩에 가져가면 자동화까지 쉽게 가능합니다.
그런데 유독 시계열 분석에서 계속 오류가 발생하더라고요.
그 이유와 대책을 알아보겠습니다.
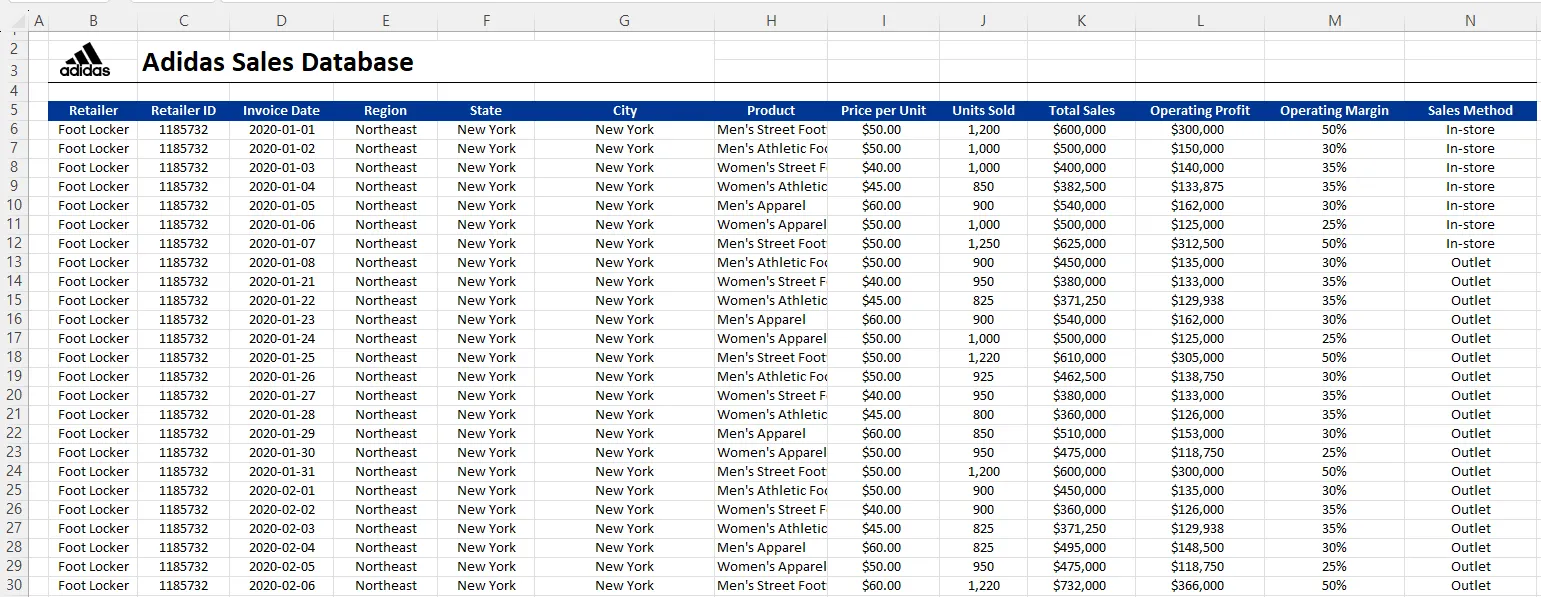
우선 엑셀로 된 데이터 파일을 준비합니다.
캐글에서 다운 받은 데이터입니다.

이걸 GPT 대화창에 그대로 업로드합니다.
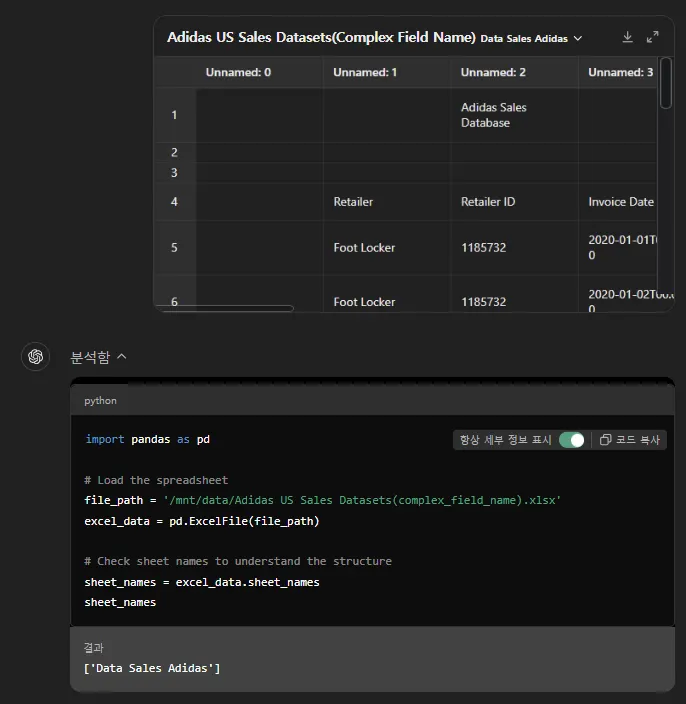
이렇게 인식이 되었어요.
엑셀에서 1~4행이 비어있고, C2 셀에는 Adidas Sales Database 라는 텍스트가 적혀있어요.
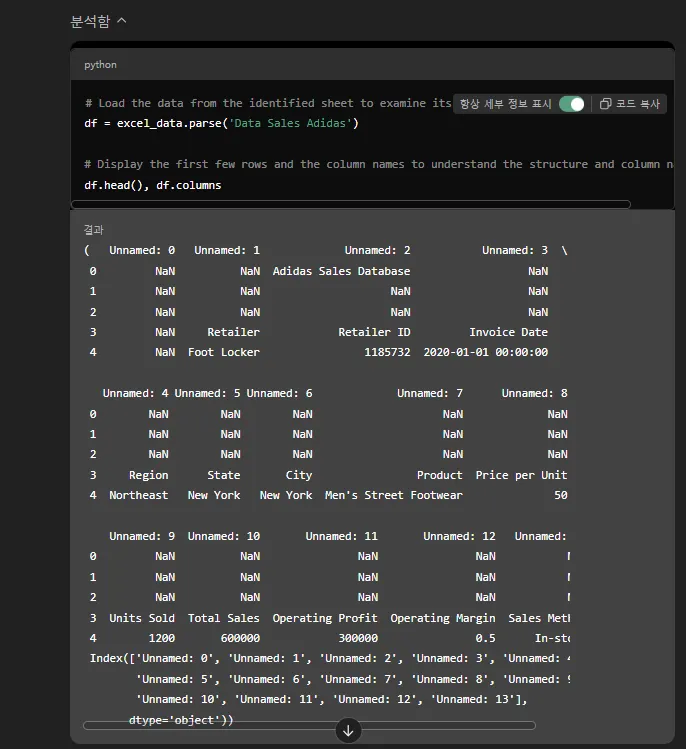
위 GPT의 코드를 보면 텅 빈 1행을 칼럼명으로 인식해버렸고,
역시나 비어있는 2행, 3행도 하나의 데이터로 인식해버렸어요.
그리고 4행은 원래는 칼럼명이지만 GPT는 이거도 하나의 데이터로 처리했네요.
하지만 똑똑한 우리의 GPT~
뭔가 이상하다고 느꼈는지, 이런 말을 합니다.
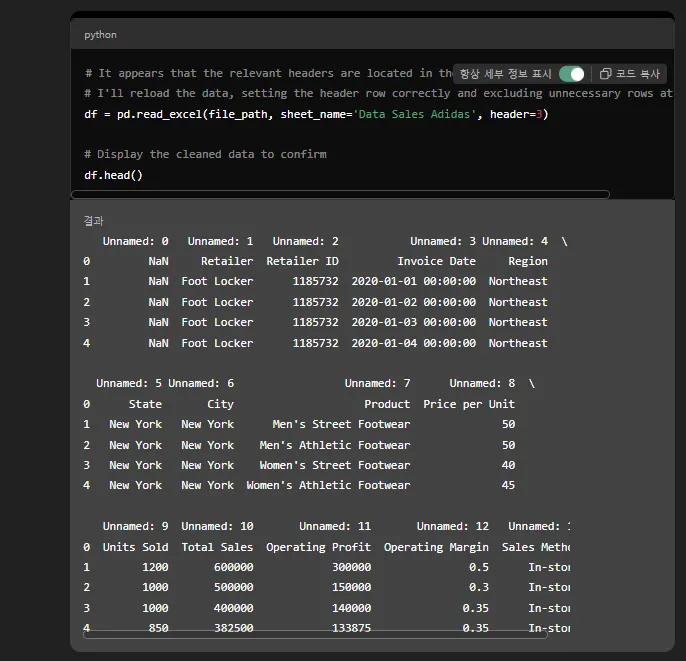
It appears that the relevant headers are located in the fourth row (index 3).
I'll reload the data, setting the header row correctly and excluding unnecessary rows at the top.
네번째 줄이 헤더(칼럼명)인 것 같다고, 자기가 정리를 좀 하겠답니다.
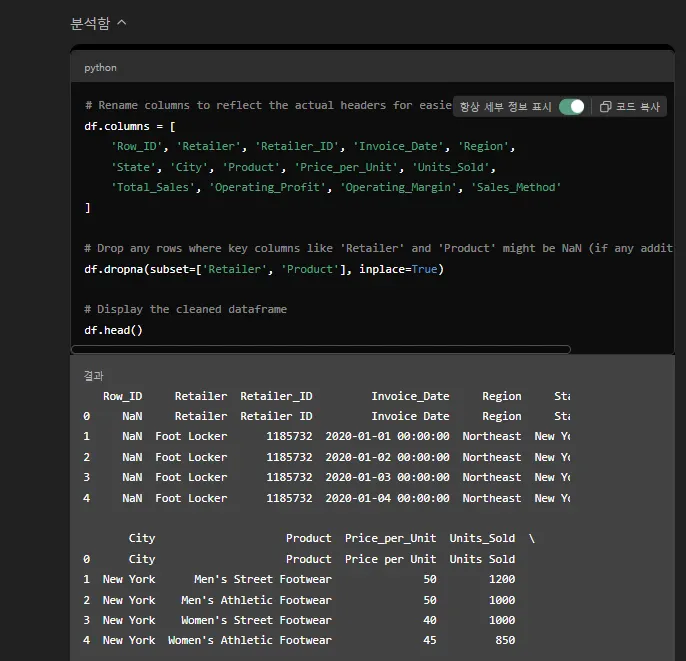
그리고는 이렇게 추가 정리를 했어요.
네번째 행에 있던 값들을 칼럼명으로 인식을 했어요.
대단합니다. GPT.
저는 엑셀 파일을 업로드 한 이후로 아무 말도 안 했어요.
GPT가 알아서 여기까지 왔습니다.
생성형 AI다 보니,
어쩔 때는 여기까지 다 하고 깔끔하게 정리를 다 끝낼 때도 있고요,
또 어쩔 때는 여기까지는 못 오고 중간쯤 하다가, “뭘 더 할까요?” 하며 멈추기도 합니다.
항상 유념해야 합니다.
GPT에서 파이썬 데이터 분석을 한다는 것은,
GPT의 판단과 그에 따른 코딩 + 파이썬 코드가 실행된 결과 도출 이라는 것을요.
파이썬 코드가 정해지면 그 실행 결과는 항상 일정하고 자동화도 가능하겠지만,
GPT의 판단은 그 때 그 때 다르기 때문에 우리가 원하는 바와 다를 수도 있어요.
이 부분은 자동화도 불가능하고요.
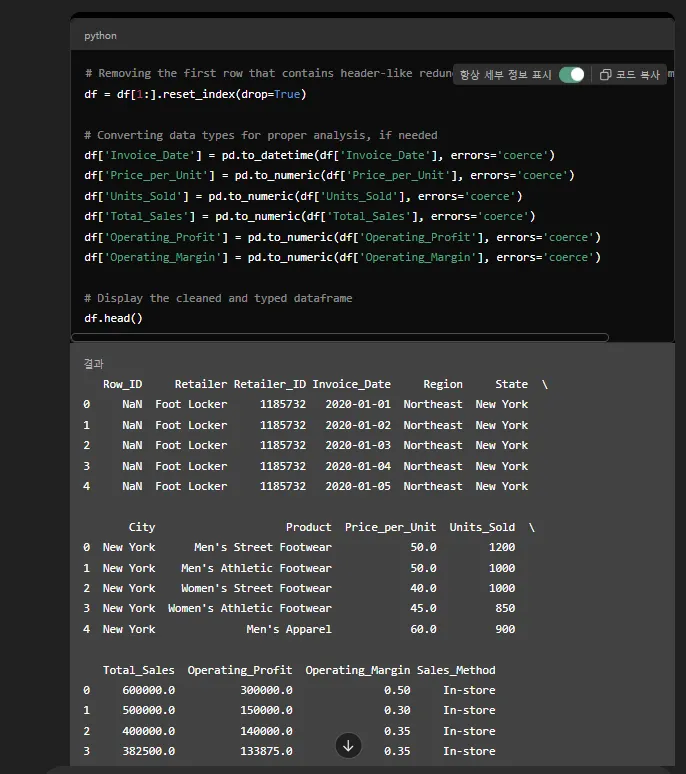
이 부분이 제일 중요합니다.
GPT가 각 칼럼의 데이터 유형을 재정의하고 있어요.
“Invoice_Date”라는 칼럼은 datetime 이라는 유형으로 바꾸고,
여러 칼럼들을 numeric 유형으로 바꾸고 있어요.
파이썬에서는 이런 데이터 유형을 dtypes 라는 이름으로 부릅니다.
언제든지 데이터프레임의 데이터 유형(dtypes)을 출력해 달라고 하면 확인할 수 있어요.
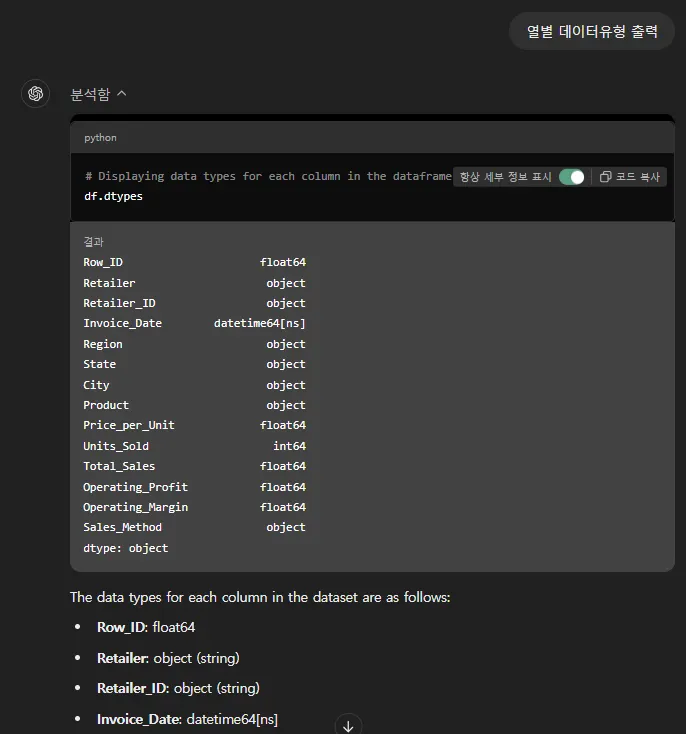
역시 GPT는 똑똑해서 여기까지 알아서 해줬네요.
하지만 항상 그런건 아닙니다. 데이터 유형을 변경하지 않을 때도 있어요.
이번에는 코랩에서 데이터를 인식시켜 보겠습니다.
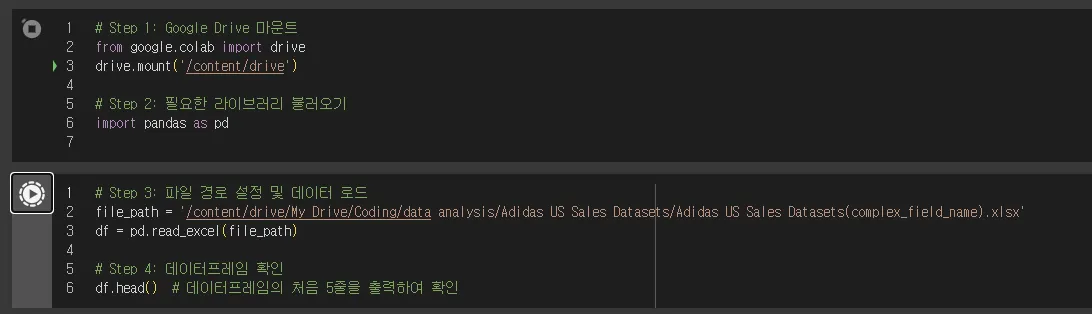
구글 코랩을 마운트해서, 구글 드라이브에 있는 엑셀 파일을 바로 인식시킵니다.
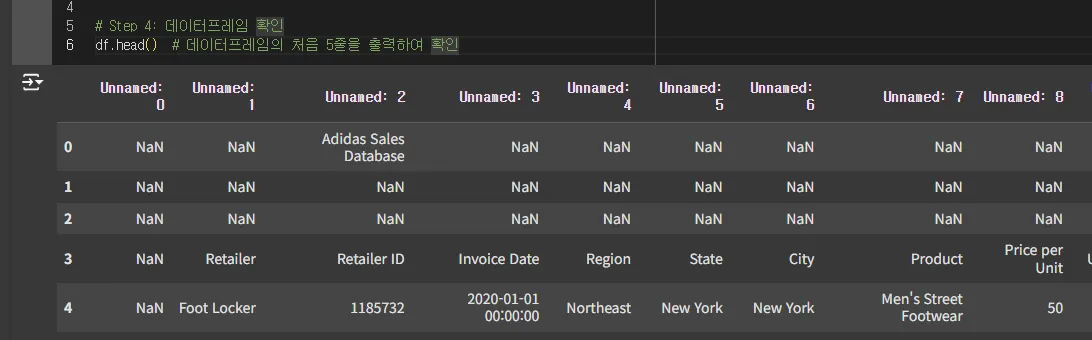
df라는 이름으로 전체 데이터가 인식이 되었어요.
이 데이터의 상위 5개만 출력시키는 df.head()를 실행해봅니다.
GPT가 처음 코딩했을 때처럼 칼럼명은 unnamed: 0 부터 13번까지로 파이썬이 이름을 붙여줬고,
엑셀의 빈 행 1, 2, 3이 여기서는 데이터로 인식이 되어버렸습니다.
4행에 있던 칼럼명이 데이터프레임의 칼럼으로 들어가지 못하고 그냥 4번째 데이터로만 들어가버렸죠.
이 상태에서 df의 dtypes를 출력시켜보면 대부분 object로 되어있습니다.
Unnamed: 3 칼럼에는 NaN도 있고, Invoice Date라는 글자도 있고, 2020-01-01 이라는 날짜도 있죠.
다 섞여있으니 판다스는 어쩔 수 없이 이걸 object로 처리해버립니다.
전부 다 날짜로 된 값만 있었다면 파이썬(판다스)이 알아서 datetime으로 인식했을건데요,
날짜가 아닌 값들도 들어있으니 모두를 포괄할 수 있는 제일 큰 범위인 object로 처리한거죠.
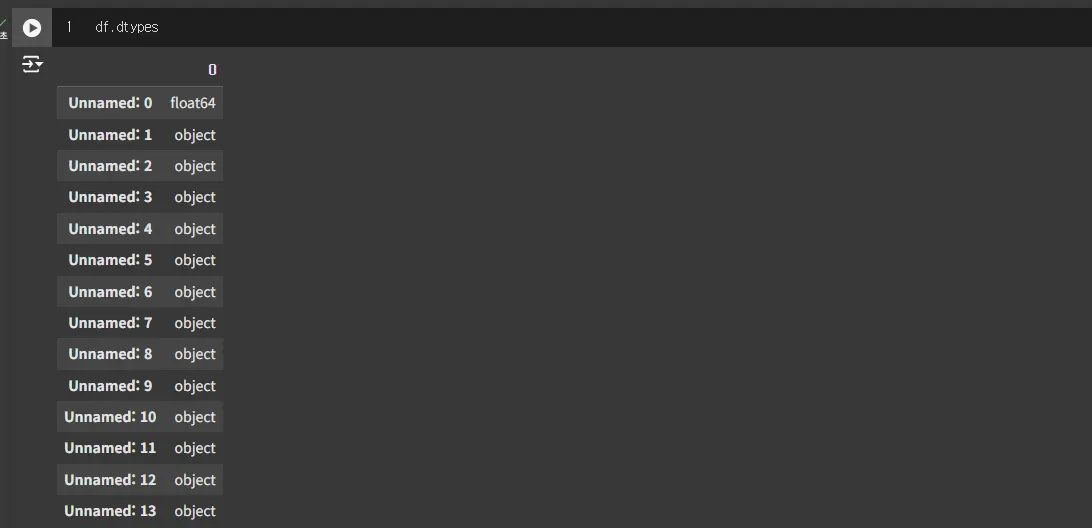
이렇게 object로 인식된 상태에서
행 1~3을 정리하고 칼럼명을 제대로 고쳐보겠습니다.
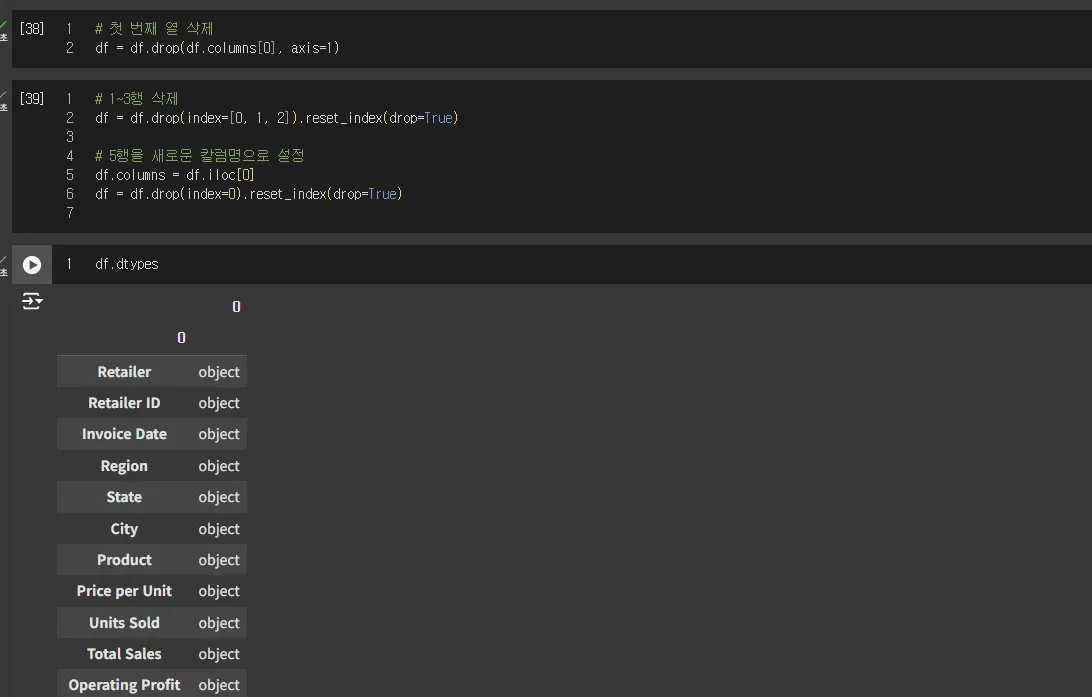
행 3개를 삭제하는 코드, 칼럼명을 다시 설정하는 코드를 적용해서 데이터를 깔끔하게 정리했습니다.
이제 df를 출력해보면 데이터는 멀쩡하고 칼럼명도 잘 적용됐습니다.
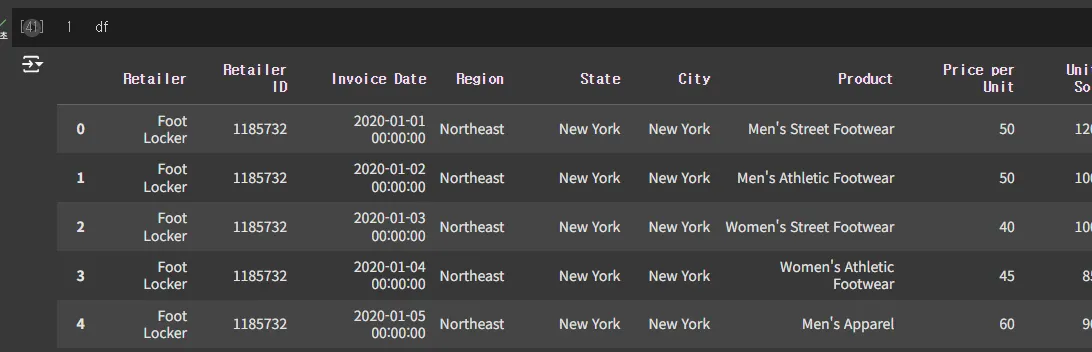
이렇게 날짜별 선그래프도 잘 그려져요.
잘 작동하는데 무슨 문제?
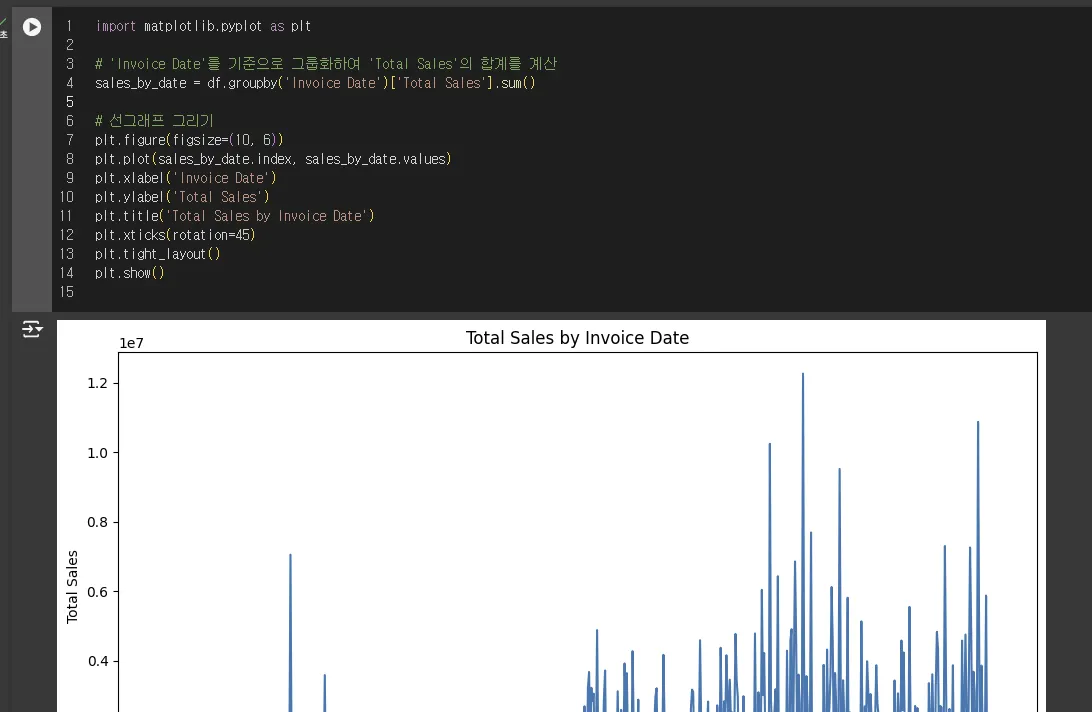
사실 이 그래프는 제대로 된 시계열 그래프가 아닙니다.
Invoice Date가 datetime이 아니라 object로 되어있기 때문에
날짜도 하나의 텍스트로 처리해버립니다.
날짜 사이에 며칠, 몇달, 몇년 간격이 있더라도 그래프에서는 그냥 옆칸이라고 그려버려요.
두 날짜가 같은 달에 해당하더라도 월별 합계가 되지도 않습니다.
날짜가 아닌 그저 텍스트일 뿐이니까 합계를 할 수가 없어요.
년월일 날짜 정보에서 년-월 정보만 추출하는 이런 명령어도 작동하지 않아요.
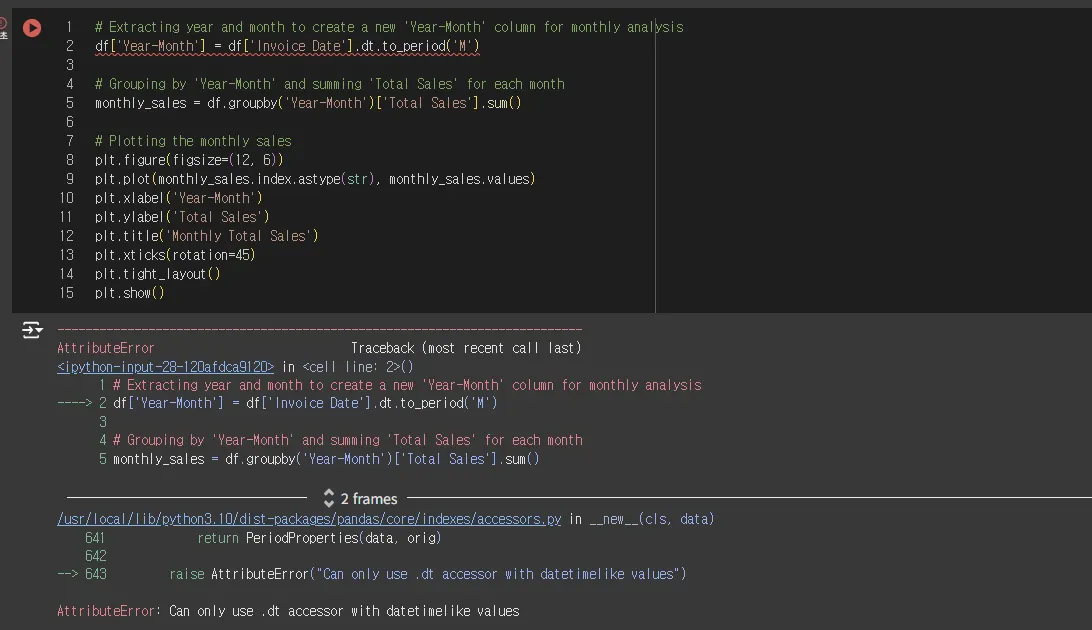
Invoice Date 칼럼을 object가 아니라 datetime으로 바꿔주는 코드를 실행합니다.
그 후에 dtypes를 확인해봐야죠.
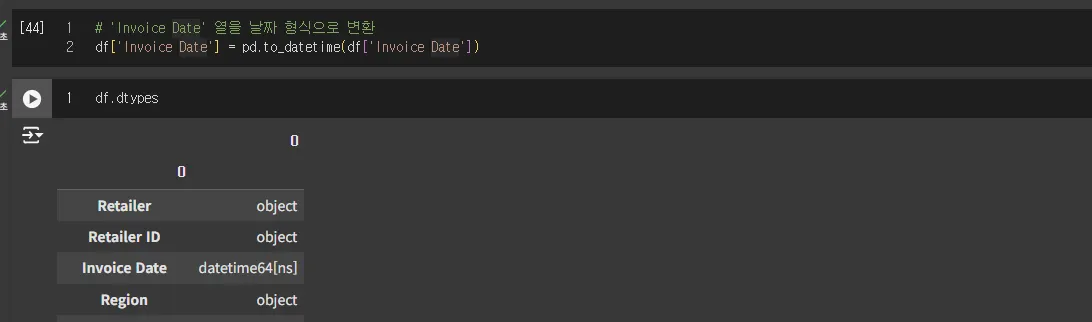
datetime으로 잘 적용이 되었네요.
이제 년 추출, 년월 추출, 월별 합계, 요일별 분석 등등이 모두 가능합니다.
간단한 datetime 관련 명령어 한두줄만 코딩해주면 되거든요.
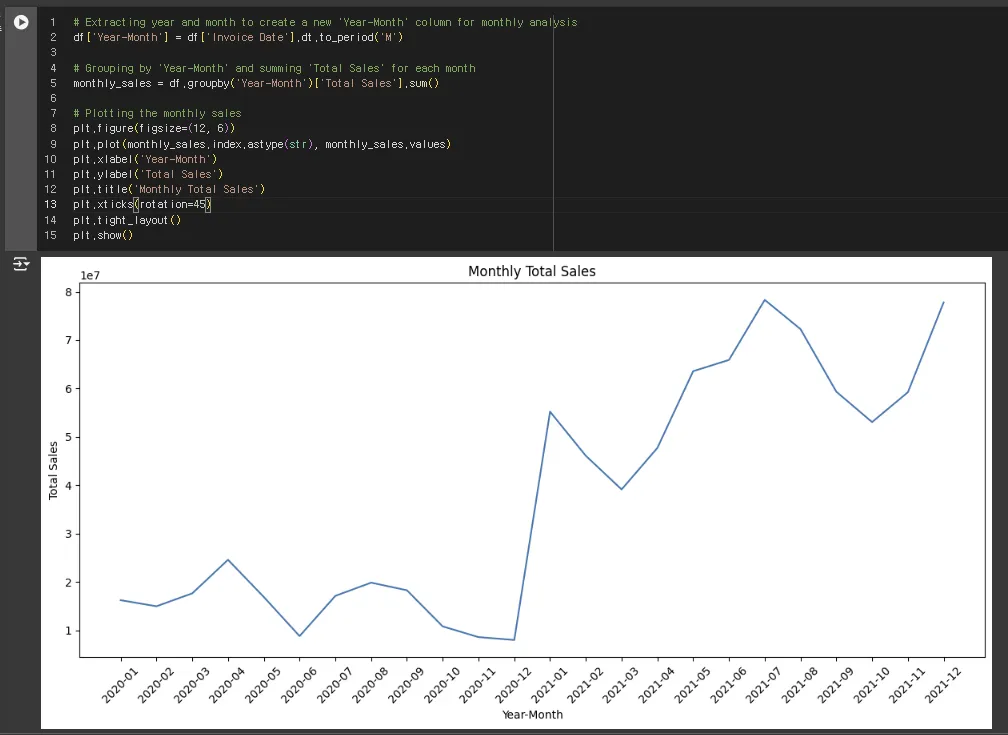
GPT에 업로드 하는 엑셀 데이터의 구조가 복잡하거나 지저분하면 이런 문제가 생깁니다.
GPT 대화창에서 데이터 처리를 하면 그나마 다행일 수 있어요. GPT가 알아서 할 때도 많으니까요.
구글 코랩에서 실행하는 경우라면 더욱 조심해야 합니다.
데이터 업로드 후에 불필요 데이터나 칼럼명 정리를 하고, 마지막에 dtypes 재정의를 해줘야 해요.
그 과정이 싫다면
처음부터 엑셀에서 데이터를 좀 정리하는 방법도 있어요.
이렇게 엑셀에서 비어있는 행이나 열은 미리 다 지우고,
불필요한 제목이나 설명이 삽입된 글도 다 지웁니다.
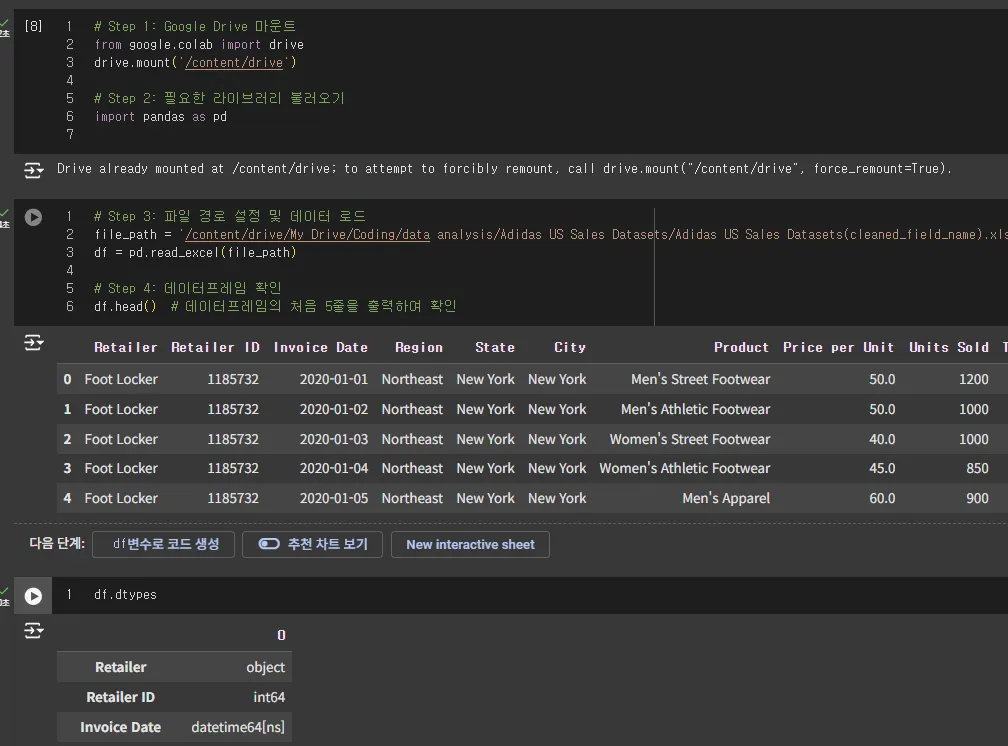
그랬더니 이렇게 엑셀 업로드했을 때부터 바로 datetime으로 인식이 됐습니다.
코드를 보면 datetime으로 변환하는 코드는 없죠. 애초에 그렇게 인식이 된겁니다.
오늘의 교훈 !
1.
데이터 칼럼에 글자, 숫자, 날짜 섞이면 다 object로 가버려서 다음 분석이 잘 안 된다.
2.
dtypes를 확인하고 적절하게 변경하자.
3.
GPT 또는 구글 코랩에 업로드하는 엑셀 파일은 깔끔하게 DB로 정리 좀 해서 올리자.