
_%25EC%25B1%2597GPT_%25EB%258D%25B0%25EC%259D%25B4%25ED%2584%25B0_%25EB%25B6%2584%25EC%2584%259D_common_mistakes_1.jpg&blockId=18f88edc-d1fd-8155-9016-f954aec632c2)
챗GPT에서 엑셀 데이터 분석하기
유료 기능인 GPT-4o에는 파일 업로드가 있지요.
여기에 엑셀(.xlsx) 파일 올리면 데이터 인식이 잘 됩니다.

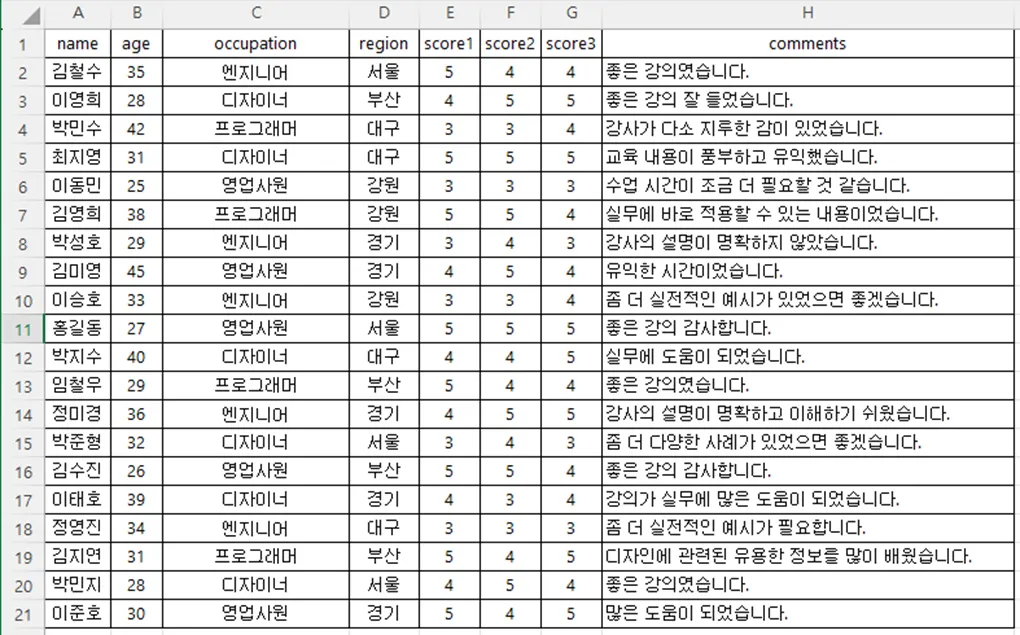
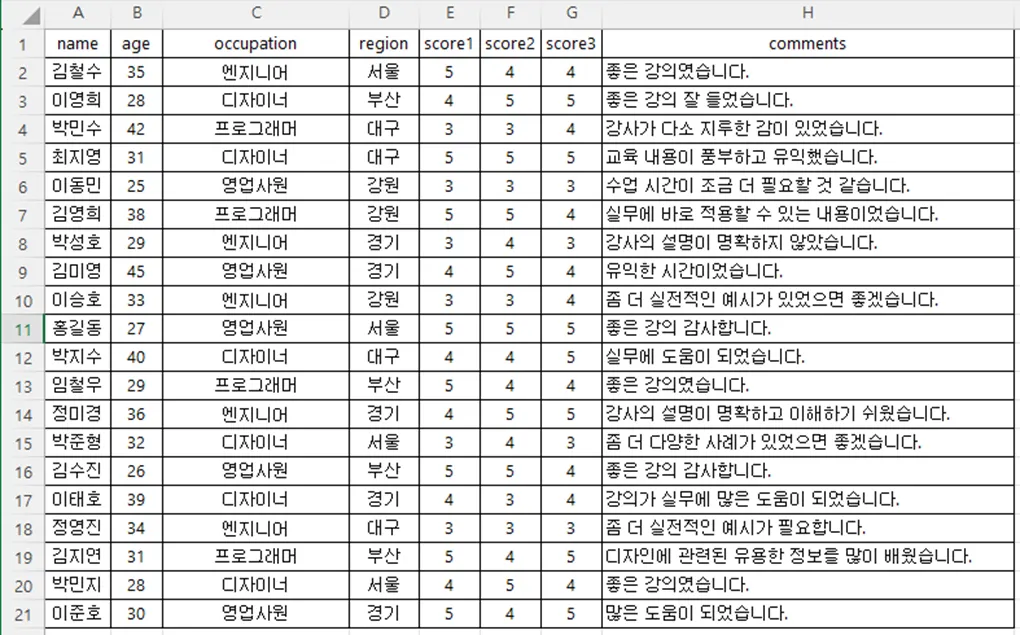
이렇게 생긴 엑셀 파일을 첨부했습니다.
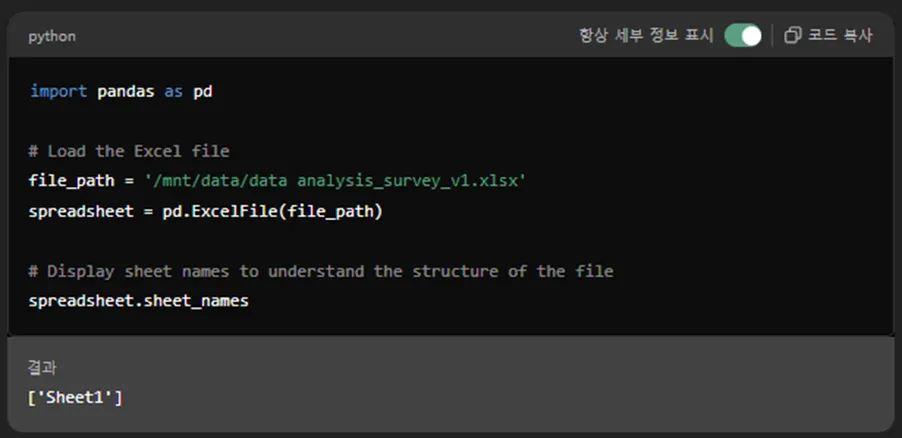
엑셀 파일을 업로드 하면 항상 만나게 되는 화면이 있죠.
바로 이 화면 !!
import pandas as pd
# Load the Excel file
file_path = '/mnt/data/data analysis_survey_v1.xlsx'
spreadsheet = pd.ExcelFile(file_path)
# Display sheet names to understand the structure of the file
spreadsheet.sheet_names
Python
복사
결과
['Sheet1']
Python
복사
그 다음엔 GPT가 이런 작업을 합니다.
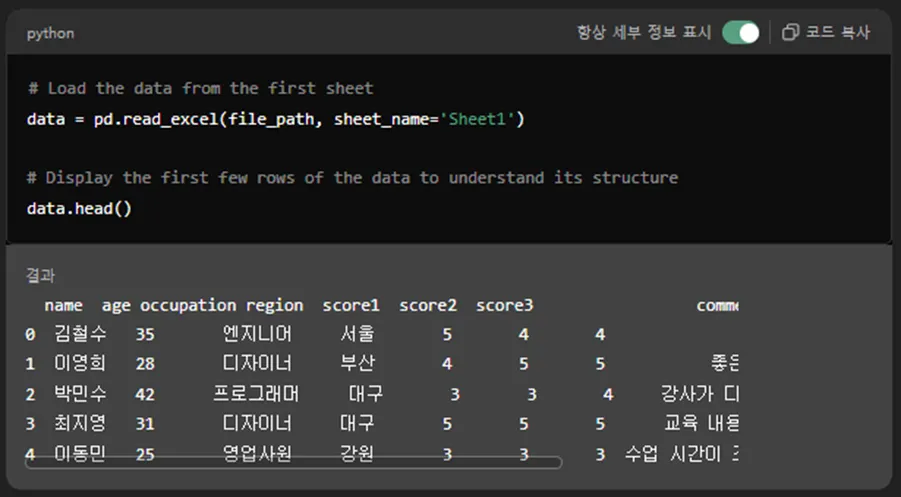
# Load the data from the first sheet
data = pd.read_excel(file_path, sheet_name='Sheet1')
# Display the first few rows of the data to understand its structure
data.head()
Python
복사
자~ 여기서부터 데이터 분석을 좀 시켜볼게요.

# Calculate basic statistics for the numerical columns in the dataset
statistics = data.describe()
import ace_tools as tools; tools.display_dataframe_to_user(name="Basic Statistics Analysis", dataframe=statistics)
statistics
Python
복사



import matplotlib.pyplot as plt
import seaborn as sns
# Setting up the visualizations
sns.set(style="whitegrid")
# 1. Distribution of Age and Scores
fig, axes = plt.subplots(2, 2, figsize=(14, 10))
# Age distribution
sns.histplot(data['age'], bins=10, kde=True, ax=axes[0, 0])
axes[0, 0].set_title('Distribution of Age')
# Score1 distribution
sns.histplot(data['score1'], bins=5, kde=True, ax=axes[0, 1])
axes[0, 1].set_title('Distribution of Score1')
# Score2 distribution
sns.histplot(data['score2'], bins=5, kde=True, ax=axes[1, 0])
axes[1, 0].set_title('Distribution of Score2')
# Score3 distribution
sns.histplot(data['score3'], bins=5, kde=True, ax=axes[1, 1])
axes[1, 1].set_title('Distribution of Score3')
plt.tight_layout()
plt.show()
Python
복사
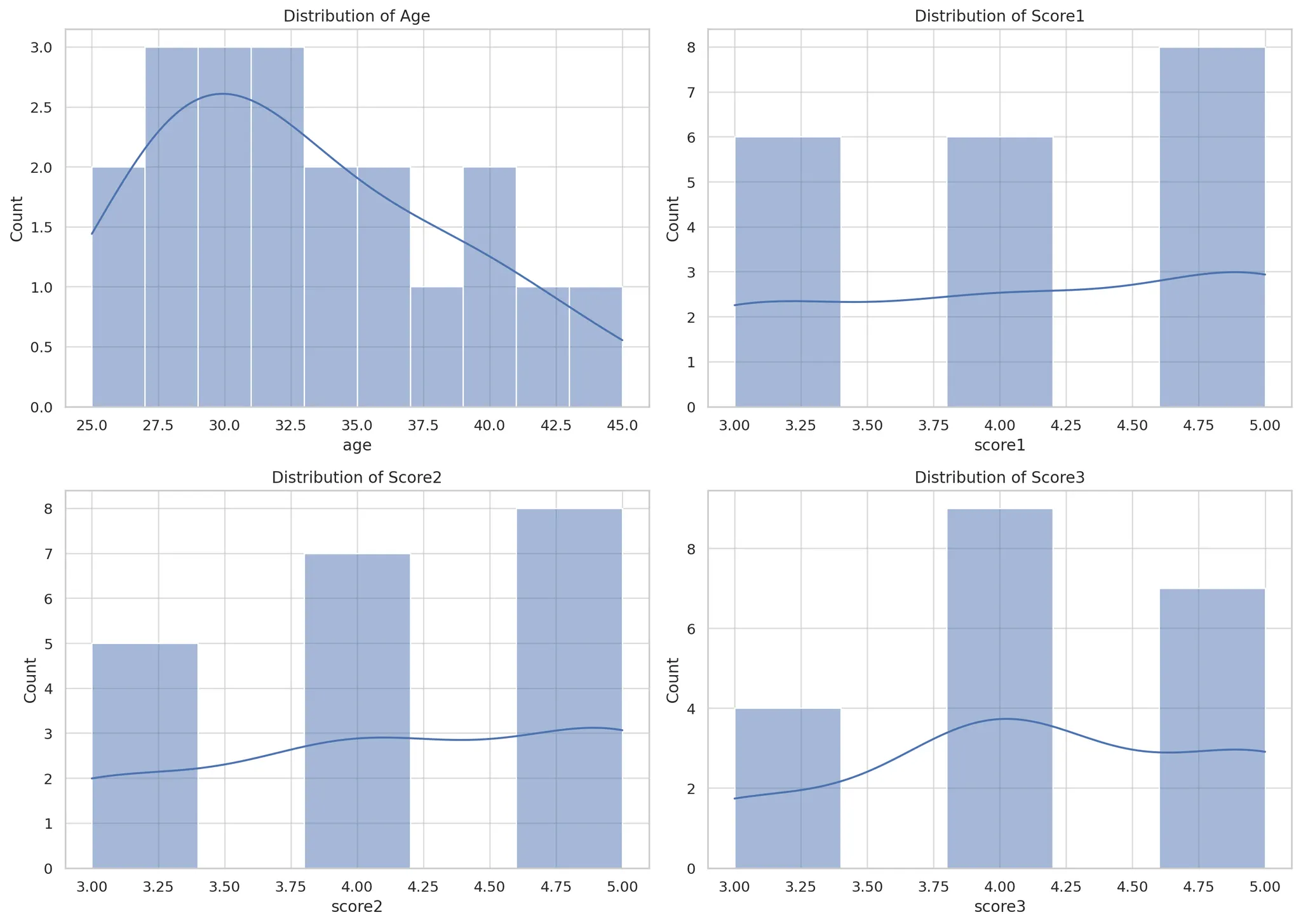


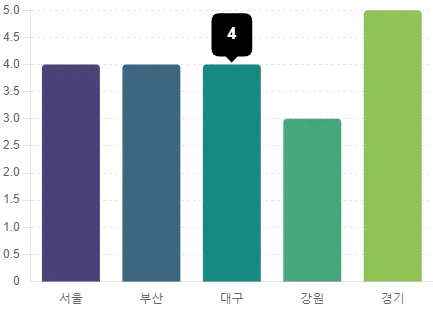
빈도 분석, 상관관계 행렬, 지역별 분석, 직업별 분석 등등 여러가지 탐색적 데이터 분석(EDA)를 해줍니다.
한글이 깨지네요.
파이썬 기본 패키지에 한글 폰트가 없어서 그렇답니다.
한글 폰트 다운받아서 GPT 대화창에 업로드 해줍니다.

이제 한글도 잘 나오네요.
GPT로 엑셀 데이터 분석을 하면 이렇게나 편리합니다.
하지만, 이렇게 되려면,
엑셀 파일의 데이터가 GPT에게 올바르게 잘 입력되어야 합니다.
그 과정에서 생길 수 있는 여러가지 오류들을 살펴보고
GPT로 엑셀 데이터 분석 잘 하는 방법을 알아보겠습니다.
엑셀 데이터가 GPT에 잘 입력되지 않는 오류 상황들
1) 첫 행이 헤더일 때
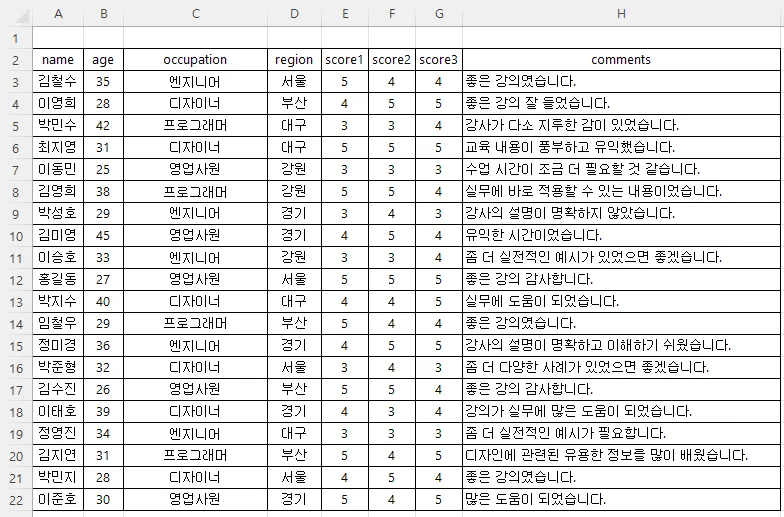
예시 파일 첨부 :
위에서 보신 예시처럼 한번에 깔끔하게 헤더가 필드명으로 인식되고
모든 데이터가 안정적인 구조로 인식이 잘 됩니다.
아예 필드명이 없이 엑셀1행부터 데이터가 시작되어도 괜찮습니다.
데이터 행에 나오는 값들을 추정해서 GPT가 나름 필드명을 지어줍니다.
저엉~ 필드명을 모르겠다 싶으면 그냥 Unnamed: 0 이런식으로 시리즈로 붙여줍니다.
2) 헤더가 비어있을 때
예시 파일 첨부 :
이렇게 엑셀 1행이 비어 있습니다.
GPT는 1행을 자동으로 헤더(칼럼명, 열 이름)로 인식합니다.
그런데 비어있으면 헷갈려하겠죠.
파일을 업로드하면 언제나처럼 판다스를 불러와서 일을 시킵니다.

# Load the data from the first sheet
df = pd.read_excel(file_path, sheet_name='Sheet1')
# Display the first few rows of the dataframe to understand its structure
df.head()
Python
복사
판다스의 read_excel 명령어를 이용해서
엑셀의 데이터를 판다스의 데이터 프레임으로 가져옵니다.
그리고 데이터가 잘 read 되었는지를 사용자에게 보여주기 위해 df.head()를 실행합니다.
로딩 된 데이터의 상위 5개 항목만 샘플로 출력시켜주는 명령어입니다.
데이터가 이상하네요.
칼럼명(필드명, 열 이름, 헤더)이 unnamed: 0부터 7까지로 정해졌고,
name, age, occupation, 등등은 필드명이 아니라 하나의 데이터 레코드로 처리됐습니다.
제일 좌측에서 아래로 있는 번호 0, 1, 2, 3, 4는 데이터 행 번호입니다.
판다스 데이터 프레임에서는 행 번호, 열 번호가 1이 아니라 0부터 시작합니다.
상위 5개 항목이니 0~4까지 출력이 된거죠.
그 중 첫번째 데이터(행 번호로는 0번)가 김철수가 아니고
name, age, occupation, 등등 이게 되버렸네요.
이러면 데이터 자체가 완전히 잘 못 읽혀진 것이기 때문에
이후로 하는 모든 데이터 분석은 완전 망한겁니다.
앗!! 하지만 우리의 GPT
여기서 멈추지 않고 자기 마음대로 다음 코딩을 합니다.

# It appears that the first row contains column headers, so we need to reload the data with the correct header row
df = pd.read_excel(file_path, sheet_name='Sheet1', header=1)
# Display the first few rows of the corrected dataframe
df.head()
Python
복사
헤더가 이상한거 같다고 다시 reload 해보겠답니다.
그러더니 엑셀 데이터 읽어오는 pd.read_excel 명령어에 header=1을 추가했습니다.
0번 행(엑셀에서 첫번째 행)이 아니라 1번 행(엑셀에서 두번째 행)을 헤더로 쓰겠답니다.
이렇게 셋팅하고 다시 df.head() 실행해서 상위 5개 데이터를 보여줍니다.
텅 비어있던 엑셀 1행이 사라지고 제대로 데이터가 인식이 되었네요.
보신 것처럼 첫 행 또는 처음 몇 행이 비어있어도 GPT가 알아서 필드명을 식별합니다.
다만, 실수를 방지하기 위해서 우리도 GPT가 실행하는 판다스 코드는 따라가봐야 합니다.
3) 칼럼이 비어 있을 때
예시 파일 첨부 :
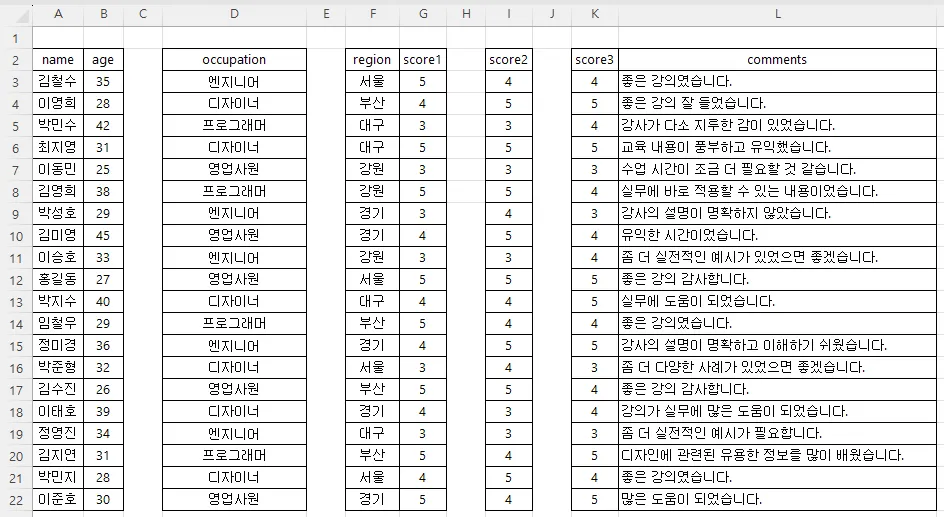
이렇게 칼럼이 비어있습니다.
이대로 GPT에 첨부해 봅니다.
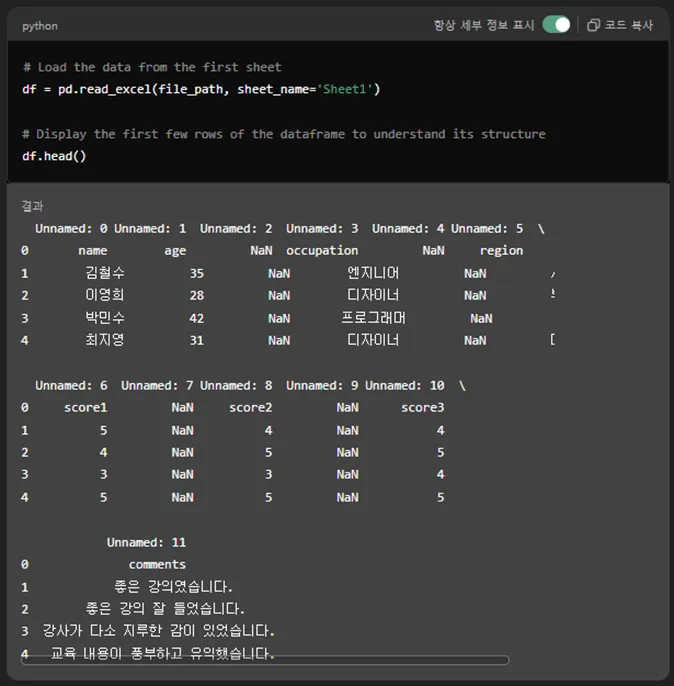
# Load the data from the first sheet
df = pd.read_excel(file_path, sheet_name='Sheet1')
# Display the first few rows of the dataframe to understand its structure
df.head()
Python
복사
마찬가지의 절차를 거쳐서 df.head()를 보여줍니다.
필드명이 인식이 안되서 Unnamed 시리즈로 붙여줬네요.
하지만 GPT가 알아서 2차 시도를 합니다.
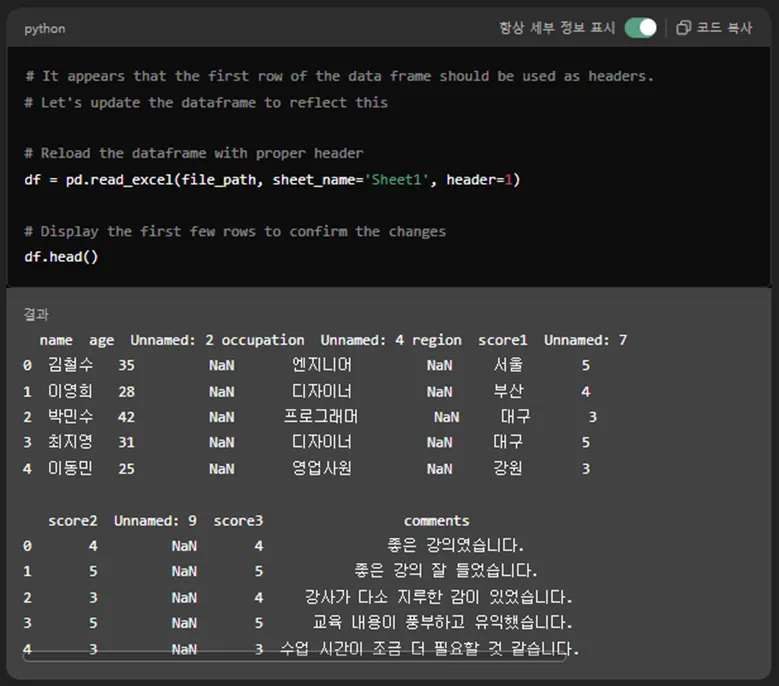
# It appears that the first row of the data frame should be used as headers.
# Let's update the dataframe to reflect this
# Reload the dataframe with proper header
df = pd.read_excel(file_path, sheet_name='Sheet1', header=1)
# Display the first few rows to confirm the changes
df.head()
Python
복사
pd.read_excel 명령어에 header=1 추가해서
아까처럼 0번 행을 지우고, 1번 행으로 필드명을 잡는 건 잘 했네요.
다만, 비어있던 열을 그대로 살려놔서 Unnamed: 2, 4, 7, 9는 남아있습니다.
후속 대화 추천에서 ‘Clean up unnecessary columns, please.’가 뜨길래 선택했습니다.
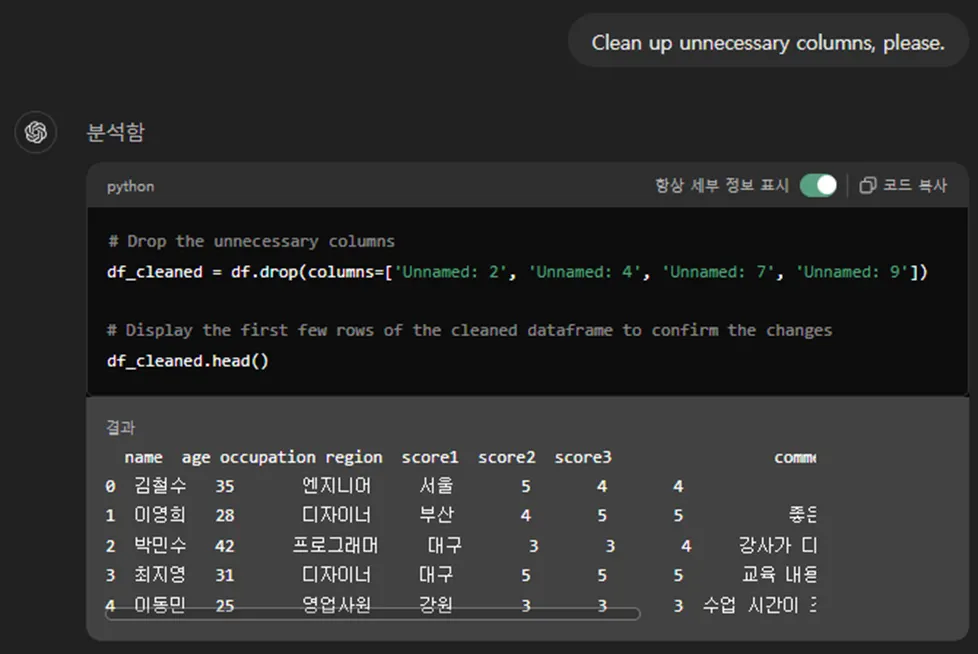
# Drop the unnecessary columns
df_cleaned = df.drop(columns=['Unnamed: 2', 'Unnamed: 4', 'Unnamed: 7', 'Unnamed: 9'])
# Display the first few rows of the cleaned dataframe to confirm the changes
df_cleaned.head()
Python
복사
기존에 Unnamed 시리즈를 포함했던 df라는 변수는 그냥 놔두고
df_cleaned라는 새로운 변수를 만들어주네요.
df에서 columns 이름이 Unnamed 2, 4, 7, 9인 칼럼을 삭제(drop)하고
그 결과를 df_cleaned에 저장했습니다. 그리고 그걸 출렸했네요.
깔끔합니다.
비어있던 행도, 비어있던 열도 다 사라졌네요.
이 이후로 하는 데이터 분석은 이제 믿을만 합니다.
다만, GPT가 df를 불러서 분석을 하는지,
df_cleaned를 불러서 분석을 하는지는
코드를 잘 봐야 합니다.
4) 데이터 값이 비어있을 때 (결측치)
예시 파일 첨부 :
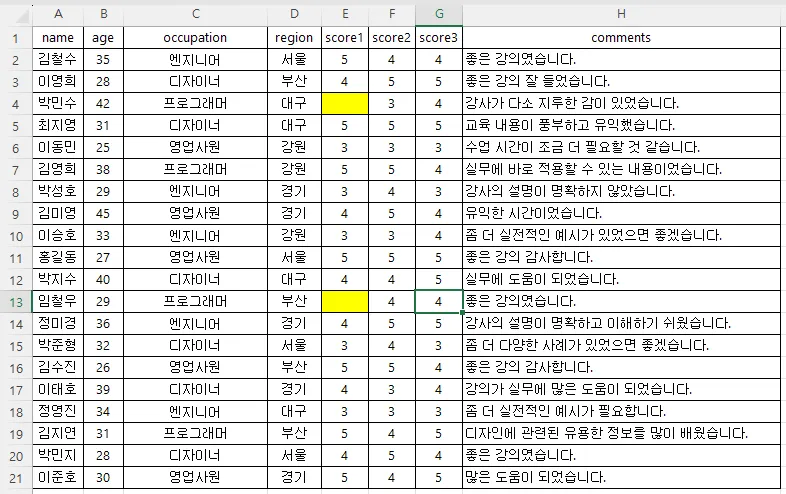
이렇게 E4, E13 데이터가 누락되어 있습니다.
이런 상태면 score1은 평균을 구할 때 전체 20으로 나누어야 할까요, 값이 있던 18로 나누어야 할까요?
이런 상황에서 score1의 평균과 score2의 평균을 비교해서 만약 score2 숫자가 더 크다면,
이건 진짜로 score2가 score1보다 높다고 말할 수 있을까요?
만약 점수를 아주 적게주는 박민수, 임철우씨가 score1은 비워놓고, score2에만 아주 짠 점수를 줬다면요?
데이터 누락이 생기면(결측치 라고 부릅니다) 이런 혼란이 생깁니다.
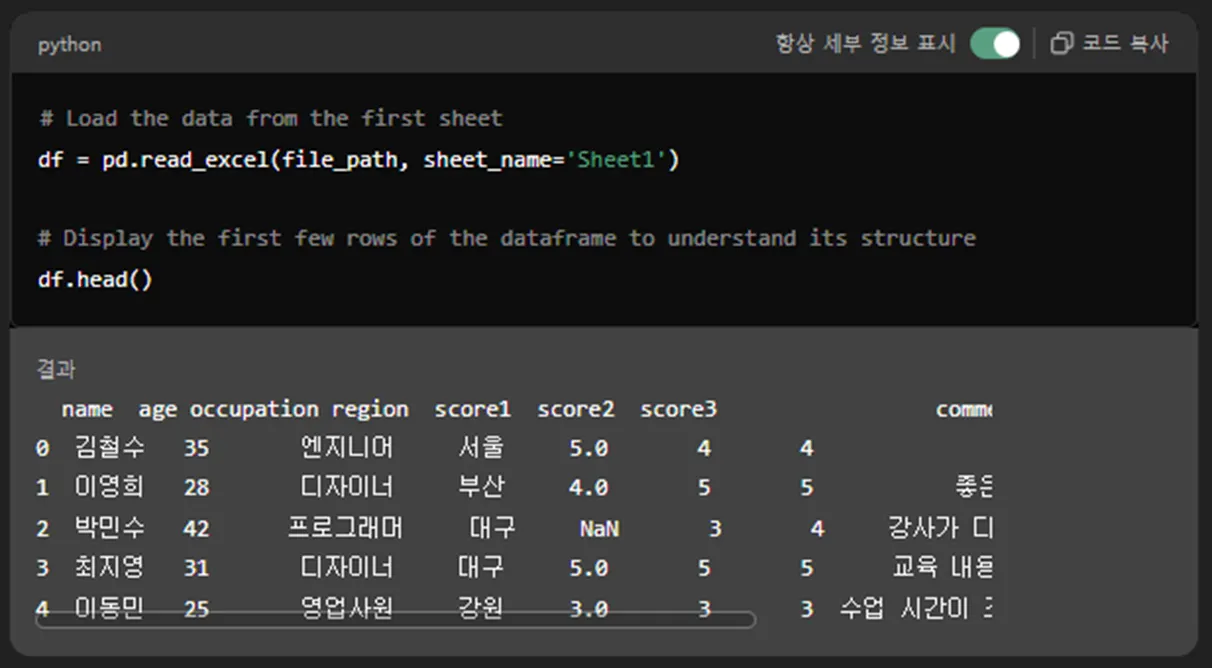
2번 행 ‘박민수’의 데이터에서 score1 부분이 ‘NaN’으로 처리되어 있습니다.
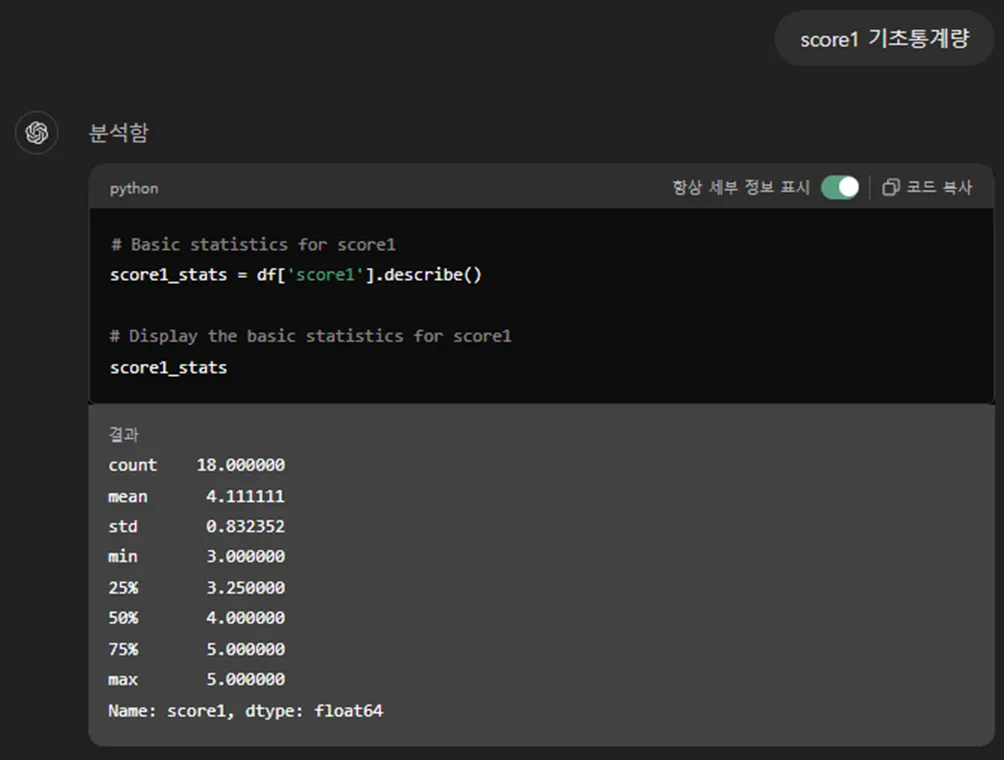
# Basic statistics for score1
score1_stats = df['score1'].describe()
# Display the basic statistics for score1
score1_stats
Python
복사
데이터의 갯수를 의미하는 count가 20이 아니라 18로 나옵니다.
평균도 합계를 20으로 나눈 값 4.1이 아니고, 합계를 18로 나눈 4.111111로 나왔습니다.
즉, GPT는 누락된 값(결측치)이 있으면 평균을 구할 때 제외하고 계산하네요.
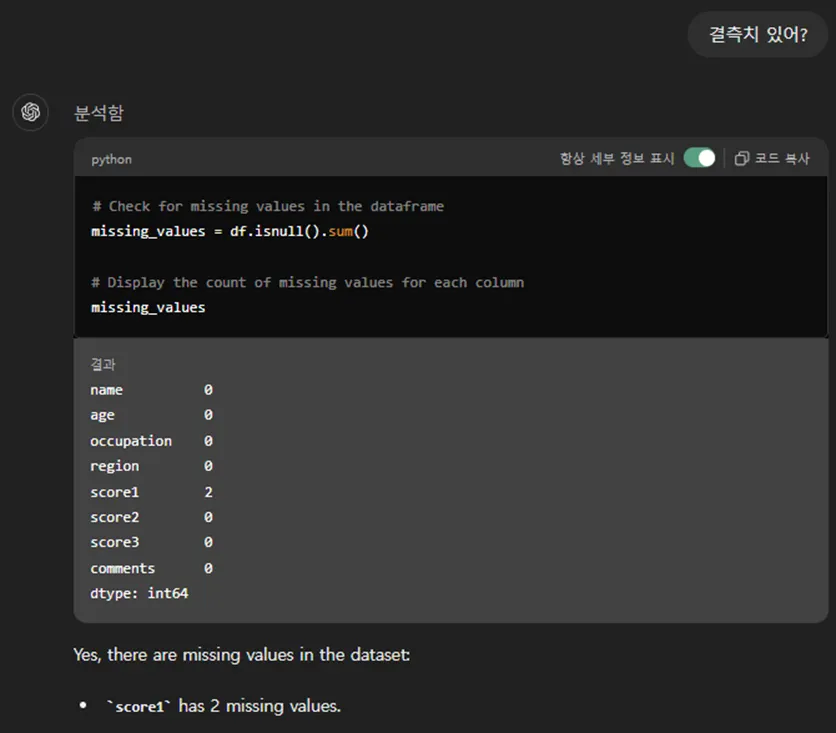
# Check for missing values in the dataframe
missing_values = df.isnull().sum()
# Display the count of missing values for each column
missing_values
Python
복사
결측치를 찾아내는 isnull() 명령어를 사용했고요, 그 결측치의 갯수를 합계하는 .sum()까지 했네요.
score1에서 결측치 2개가 발견되었다고 합니다.
GPT는 데이터 분석 전문가이기도 하니까, 결측치 처리 방법을 물어봅니다.

결측치는 이후 데이터 분석 단계에서 여러 혼란을 초래할 수 있습니다.
본격적인 데이터 분석에 앞서서 데이터 전처리 과정에서 적절한 조치를 취하는 것이 좋습니다.
GPT의 추천대로 결측치가 있는 데이터 레코드 자체를 삭제하거나, 다른 값으로 대체하면 됩니다.
물론, GPT에게 평균값으로 대체해줘 라고 말하면 그렇게 해줍니다.
우리가 업로드 했던 원본 엑셀 파일을 수정하는 것이 아니라,
그 엑셀 파일에서 읽어왔던 데이터, 지금은 판다스를 이용해서 df라는 이름의 변수로 지정한
그 데이터 프레임에서 해당 결측치 데이터를 수정합니다.
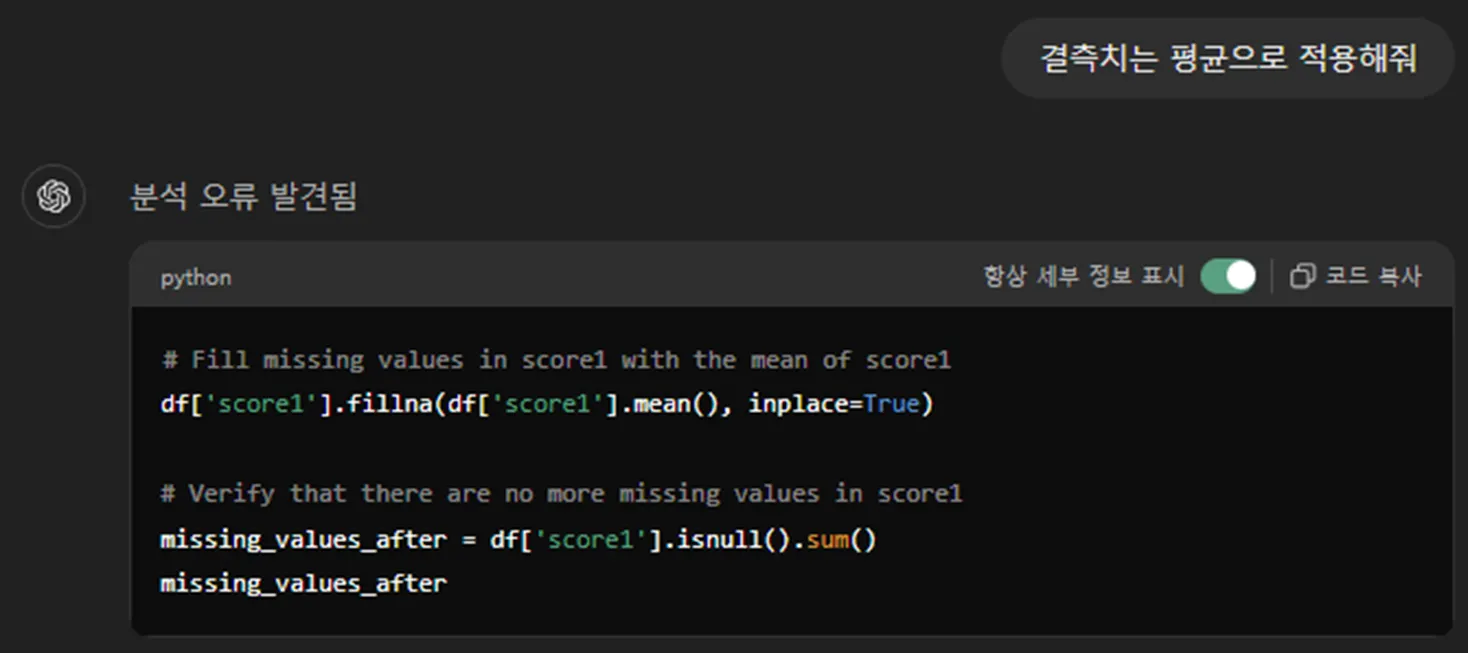
.fillna #결측치를 찾아서 다른 값을 덮어쓰는 명령어
df[‘score1’].mean() #score1 칼럼의 평균을 구하는 명령어
5) 데이터가 여러 시트에 나누어져 있을 때
예시 파일 첨부 :

이렇게 여러 개의 탭으로 나눠져 있습니다.
엑셀 파일을 업로드 하니 하나의 파일에서 시트 5개를 모두 인식했습니다.

# Load each sheet into a separate DataFrame and display the first few rows of each to understand their contents
sheet1 = pd.read_excel(spreadsheet, 'Sheet1')
sheet2 = pd.read_excel(spreadsheet, 'Sheet2')
sheet3 = pd.read_excel(spreadsheet, 'Sheet3')
sheet4 = pd.read_excel(spreadsheet, 'Sheet4')
sheet5 = pd.read_excel(spreadsheet, 'Sheet5')
sheet1_head = sheet1.head()
sheet2_head = sheet2.head()
sheet3_head = sheet3.head()
sheet4_head = sheet4.head()
sheet5_head = sheet5.head()
sheet1_head, sheet2_head, sheet3_head, sheet4_head, sheet5_head
Python
복사
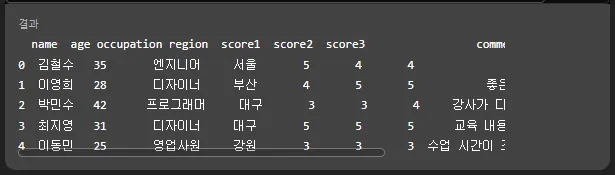
각각의 Sheet를 각각의 데이터 프레임으로 만들었습니다.
그리고 각각의 .head()를 출력해주네요.
이렇게 각각 나옵니다.

# Merge all sheets into one DataFrame
merged_df = sheet1.copy()
# Merge scores
merged_df = pd.merge(merged_df, sheet2, on='name')
merged_df = pd.merge(merged_df, sheet3, on='name')
merged_df = pd.merge(merged_df, sheet4, on='name')
# Merge comments
merged_df = pd.merge(merged_df, sheet5, on='name')
import ace_tools as tools; tools.display_dataframe_to_user(name="Merged Data", dataframe=merged_df)
merged_df.head()
Python
복사
GPT의 프리셋 질문에 있는 merge 요청을 선택했습니다.
sheet1 데이터 프레임을 copy해서 일단 merged_df에 넣었고요,
sheet2 내용을 읽어와서 ‘name’을 기준으로 merged_df에 삽입을 했고요,
sheet3, sheet4, sheet5에 대해서도 동일 작업을 반복했습니다.
그리고 이렇게 누적으로 합쳐진 merged_df를 .head()로 보여주네요
마치 제일 처음 사용했던 v1 파일처럼 깔끔한 데이터 프레임으로 합쳐졌습니다.
6) 숫자가 아닌 문자가 섞여있을 때 (1/2)
예시 파일 첨부 :
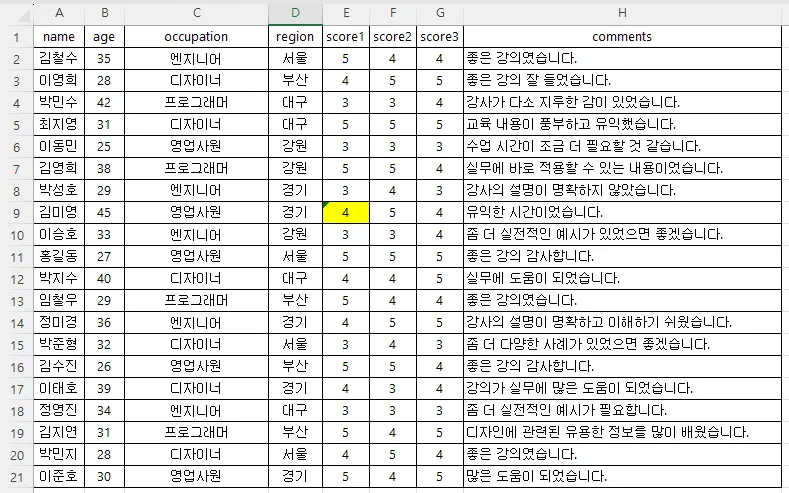
이렇게 E9 셀의 값이 서식이 ‘숫자’가 아니라 ‘문자’입니다.

엑셀에서 E열(E2:E21)을 드래그 해보면 우측 아래 요약에서
합계 78, 개수 20, 평균 4.105263158 이라고 나옵니다.
합계 78에 개수 20이면 평균은 3.9가 맞지요.
이 평균 4.105263은 78 나누기 19를 해서 나온 값입니다.
즉, 엑셀에서는 문자는 일종의 결측치처럼 처리가 되버린거죠.

하지만 GPT에서 엑셀 파일을 읽어오는 과정에서 이건 그냥 숫자가 되어 버렸습니다.

score1에 대한 합계 계산 시 E9 셀의 4를 포함하여 합계 82로 계산했네요.
‘4는 엑셀에서는 문자이지만, 판다스에서는 그냥 숫자 4로 처리됩니다.
score1의 count는 20이고, mean은 4.100000 입니다.
4를 문자로 처리해서 제외시켜버린 엑셀은 78 나누기 19를 해서 4.105263158,
4를 숫자로 처리해서 포함시킨 GPT는 82 나누기 20을 해서 4.100000
차이가 나네요
7) 숫자가 아닌 문자가 섞여있을 때 (2/2)
예시 파일 첨부 :

이렇게 진정한 문자 ‘4점’이 섞여 있습니다.

pd.read_excel 결과에서도 ‘4점’이 잘 보여요.

“score1 기초통계량 분석”을 시켰을 때
.describe 명령어에 count, mean, min, max가 나오는게 아니네요.
count, unique, top, freq가 나오고 있습니다.
이건 수치 데이터가 아닌 문자 데이터에 대한 분석 결과입니다.
‘4점’이라는 문자가 포함되어 있어서, 전체 칼럼을 문자형 데이터로 분석을 했네요.
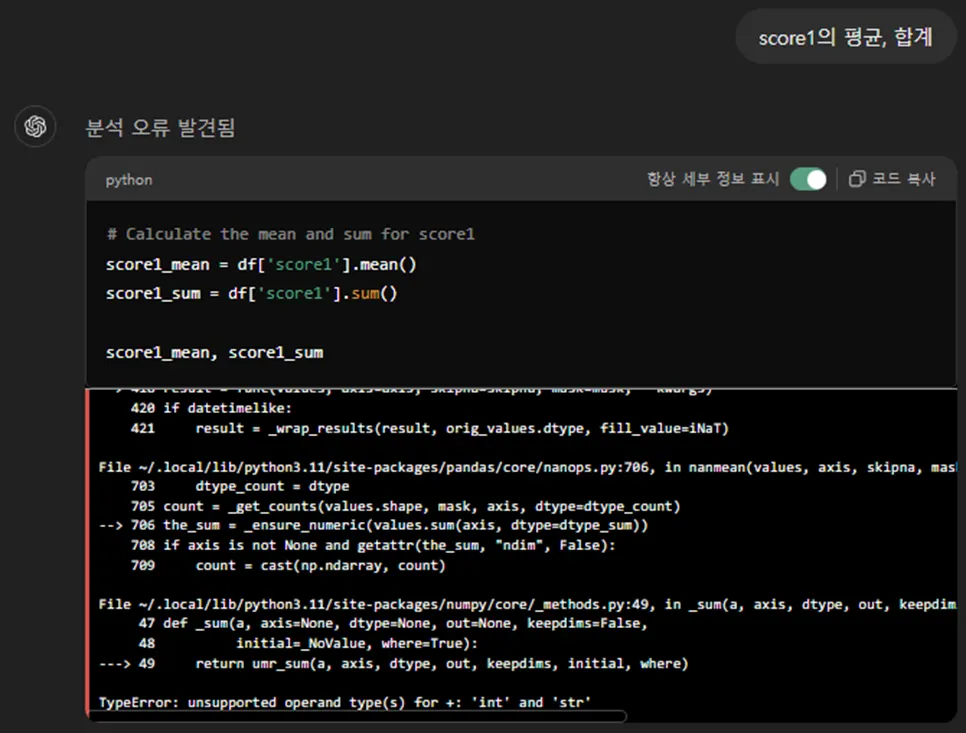
score1의 평균과 합계를 구하라고 하니 오류가 납니다.
numeric(수치형 데이터)이 아니라서 발생하는 오류라고 하네요.

오류에 대처하기 위해 GPT 스스로 2차 코딩을 했네요.
df['score1'] = pd.to_numeric(df['score1'], errors='coerce’)
pd.to_numeric # 해당 칼럼의 데이터를 수치형 데이터로 변환해라
errors='coerce’ # 수치형이 아닌 invalid 데이터는 NaN으로 처리해라
이 처리를 하고 나니,
E9 셀 값 ‘4점’을 NaN(결측치)으로 처리해서
GPT는 합계 78, 개수 19, 따라서 평균 4.1025라고 말했습니다.
이런 경우를 대비해서 데이터 정합성 검증을 할 필요가 있습니다.
_280x280.jpg&blockId=18f88edc-d1fd-81fa-9bde-dee3e34003b6)
데이터 정합성 검증해줘
# Check for missing values
missing_values = data.isnull().sum()
# Check for duplicates
duplicate_rows = data.duplicated().sum()
# Convert scores to numeric and check for invalid values (e.g., non-numeric)
data['score1'] = pd.to_numeric(data['score1'], errors='coerce')
data['score2'] = pd.to_numeric(data['score2'], errors='coerce')
data['score3'] = pd.to_numeric(data['score3'], errors='coerce')
invalid_score1 = data['score1'].isnull().sum()
invalid_score2 = data['score2'].isnull().sum()
invalid_score3 = data['score3'].isnull().sum()
# Adjusting the code to properly format the integrity check summary
integrity_check = {
'Missing Values': missing_values,
'Duplicate Rows': pd.Series([duplicate_rows], index=['count']),
'Invalid Score1 Entries': pd.Series([invalid_score1], index=['count']),
'Invalid Score2 Entries': pd.Series([invalid_score2], index=['count']),
'Invalid Score3 Entries': pd.Series([invalid_score3], index=['count'])
}
integrity_check_df = pd.DataFrame(integrity_check)
tools.display_dataframe_to_user(name="Data Integrity Check Summary", dataframe=integrity_check_df)
integrity_check_df
Python
복사

Here is the summary of the data integrity check:
•
Missing Values: No missing values in any column.
•
Duplicate Rows: No duplicate rows found.
•
Invalid Score Entries:
◦
Score1 has 1 invalid entry.
◦
Score2 has no invalid entries.
◦
Score3 has no invalid entries.
This indicates that the data is mostly clean, with only one invalid entry in the score1 column. If you need further cleaning or specific actions to handle the invalid entries, please let me know!
_280x280.jpg&blockId=18f88edc-d1fd-8156-b1e9-ee20e2093a21)
invalid entries가 뭔지 상세하게 설명해줘

The invalid entry in the ‘score1’ column is:
•
Row 7:
◦
Name: 김미영
◦
Age: 45
◦
Occupation: 영업사원
◦
Region: 경기
◦
Score1: NaN (invalid entry)
◦
Score2: 5
◦
Score3: 4
◦
Comments: 유익한 시간이었습니다.
The issue is with the ‘score1’ value, which is missing or was unable to be converted to a numeric value. If you need further action on this, such as correcting or removing this entry, please let me know.
이렇게 Row7에서 김미영의 데이터 중에 score1이 NaN (invalid entry)라고 알려줍니다.
역시나 GPT와 대화하면서 삭제 또는 대체 조치를 해야겠습니다.
이번 글은 여기서 마치고,
다음 글에서 몇가지 경우를 더 살펴보도록 하겠습니다.