
_%25ED%258C%258C%25EC%259D%25B4%25EC%258D%25AC_%25ED%2599%2598%25EA%25B2%25BD_%25EA%25B5%25AC%25EC%25B6%2595.jpg&blockId=18f88edc-d1fd-810a-b47b-cb2ac02a0701)
안녕하세요.
오늘은 챗GPT 활용 데이터 분석을 할건데요,
데이터 분석을 위한 파이썬 코드를 공부해보려고 합니다.
물론 챗GPT에게 배울겁니다.
지난 번에 챗GPT 데이터 분석 기초편을 알아봤습니다.
이 때는 챗GPT 대화창에서 모든 데이터 분석을 다 진행했었죠.
하지만 이렇게 하면 금방 한계가 옵니다.
챗GPT 대화창에서 데이터 분석하면 헷갈리는 이유
일단 분석을 위한 샘플 데이터 10개를 만들었습니다.
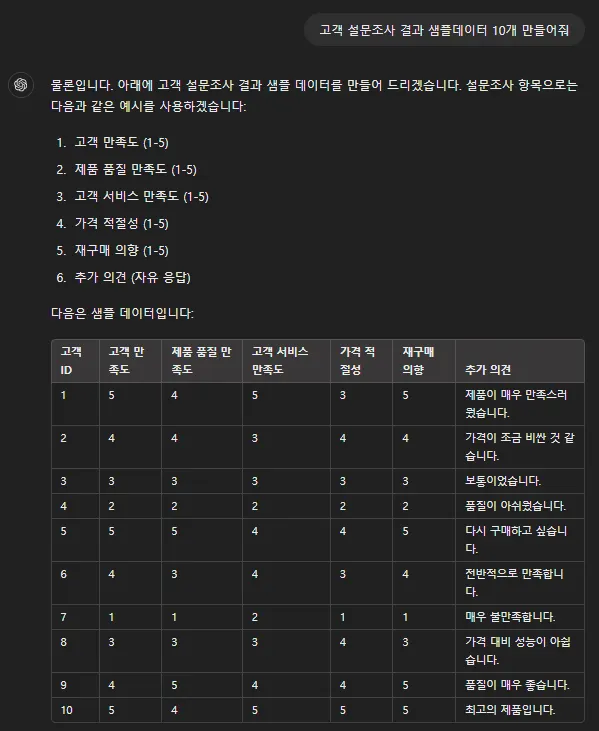
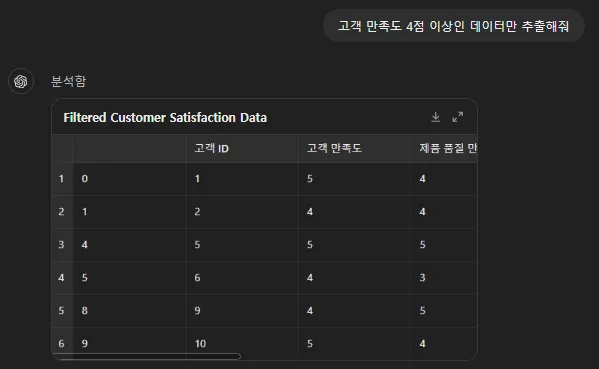
고객 만족도 4점 이상이라는 기준으로 데이터 추출을 했습니다.
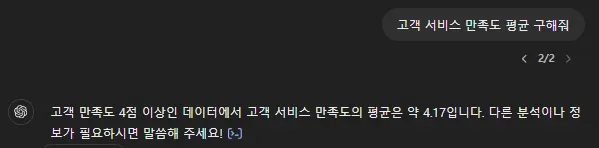
고객 서비스 만족도 평균을 물어봅니다.
아까 대화 나눈 ‘고객 만족도 4점 이상’이라는 필터 먹힌 범위 내에서 평균을 구해서 4.17 이라고 대답하네요.
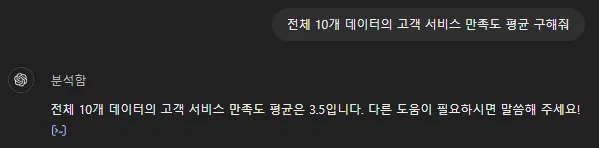
제가 알고 싶었던 건 전체 10개 데이터의 평균이었고,
구체적으로 명시하니 10개의 평균은 3.5라고 대답해줍니다.
저의 질문에서는 둘 다 동일하게 “고객 서비스 만족도 평균”을 구해달라는 것이었지만,
데이터 분석을 하던 흐름에 따라서 대답이 달라집니다.
챗GPT는 우리와의 대화 이력을 반영하니까 당연히 이렇게 되는거죠.
이래서 데이터 분석하다가 큰 실수를 할 수도 있습니다.
내가 물어본 의도와 챗GPT가 대답한 숫자의 기준이 다를 수 있는거죠.
챗GPT 대화창에서 헷갈리지 않는 방법
헷갈리지 않으려면 파이썬 코드를 봐야 합니다.
나의 분석 지시가 어떤 식으로 반영이 되었는지 확인해야 합니다.
고객 만족도 4점 이상인 데이터만 추출하라는 프롬프트에 대해서
아래와 같이 파이썬으로 실행을 했습니다.
# DataFrame으로 변환
df = pd.DataFrame(data)
# 고객 만족도 4점 이상인 데이터 추출
filtered_df = df[df["고객 만족도"] >= 4]
import ace_tools as tools; tools.display_dataframe_to_user(name="Filtered Customer Satisfaction Data", dataframe=filtered_df)
filtered_df
Python
복사
df라는 이름의 데이터 프레임에서 “고객 만족도”라는 칼럼의 값이 4 이상인 데이터들만 추출해서 filtered_df라는 새로운 변수에 할당을 했습니다.
즉,
10개의 전체 데이터는 df라는 데이터 프레임에 들어있고,
그 중 만족도 4 이상인 데이터만 추출해서 filtered_df에 넣었죠.
그 다음에 “고객 서비스 만족도 평균 구해줘”라는 프롬프트에 대한 답변에서 코드를 열어봅니다.
“고객 서비스 만족도” 필드의 값들만 추출할 때, df에서 추출한 것이 아니고, filtered_df에서 추출했죠.
전체 10개 데이터에서 가져온 평균이 아니고,
위 대화에서 이미 만족도 4 이상으로 추출했던 filtered_df 데이터에서만 “고객 서비스 만족도” 평균을 구한거죠.
이래서 평균이 4.17이 나왔습니다.
# 고객 서비스 만족도 평균 계산
average_service_satisfaction = filtered_df["고객 서비스 만족도"].mean()
average_service_satisfaction
Python
복사
이번에는 “전체 10개 데이터의 고객 서비스 만족도 평균 구해줘”라는 프롬프트에 대한 실행 코드를 확인해 봅니다.
전체 10개라고 명시를 했더니 filtered_df가 아니라 전체 데이터인 df에서 평균을 가져왔네요.
이래서 평균이 3.5가 나왔습니다.
#전체 데이터에서 고객 서비스 만족도 평균 계산
overall_average_service_satisfaction = df["고객 서비스 만족도"].mean()
overall_average_service_satisfaction
Python
복사
이렇게 코드를 확인해보면 챗GPT와 대화하며 데이터 분석하는 과정에서의 실수를 줄일 수 있습니다.
하지만 그러려면 결국 우리는 코드 공부를 해야겠군요.
하지만 코딩 전체를 공부해야 하는 것은 아니고,
우선은 파이썬만 할거고, 그 중에서도 데이터 분석에 가장 많이 쓰이는 Pandas만 하면 됩니다.
자~ 그럼 포기하지 말고 가 봅시다~
파이썬 실행 환경 구축
챗GPT에게 과외를 좀 받아보겠습니다.
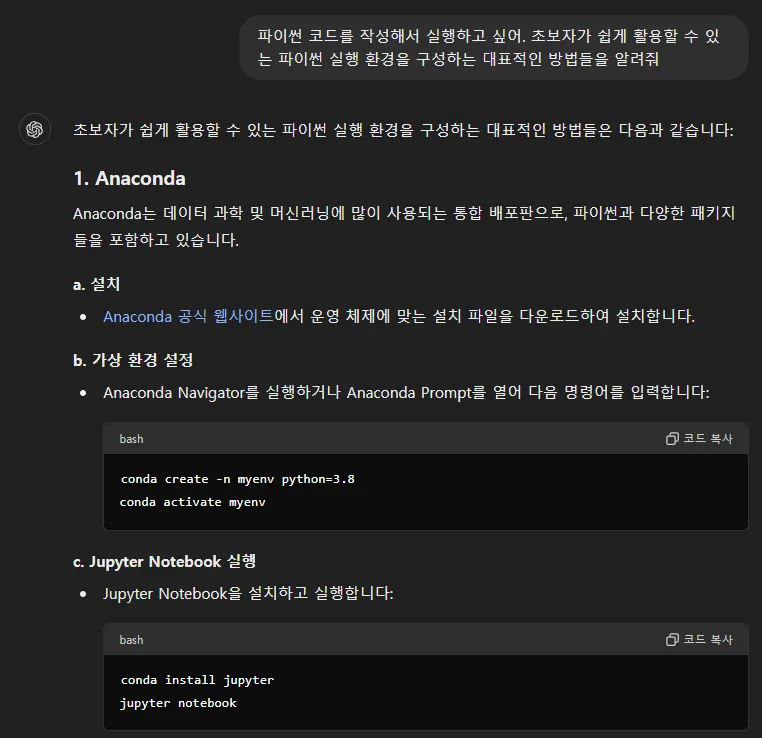




초보자가 설치하기 쉬운 파이썬 실행 환경
1) 주피터 노트북 뿐만 아니라 여러 데이터 분석 패키지를 모두 포함한 아나콘다를 설치한다
2) 주피터 노트북 환경만 설치한다
3) 내 PC에 설치하지 않고 구글 코랩에서 실행한다
방법#1) 아나콘다 설치
Numpy, Pandas, Matplotlib, Jupyter Notebook 등 여러 패키지를 포함하는 파이썬 배포판
Spyder, JupyterLab 등의 IDE(통합개발환경)를 포함하여 사용자가 코드를 작성하고 실행할 수 있는 통합된 환경을 제공
아나콘다 설치파일 다운로드

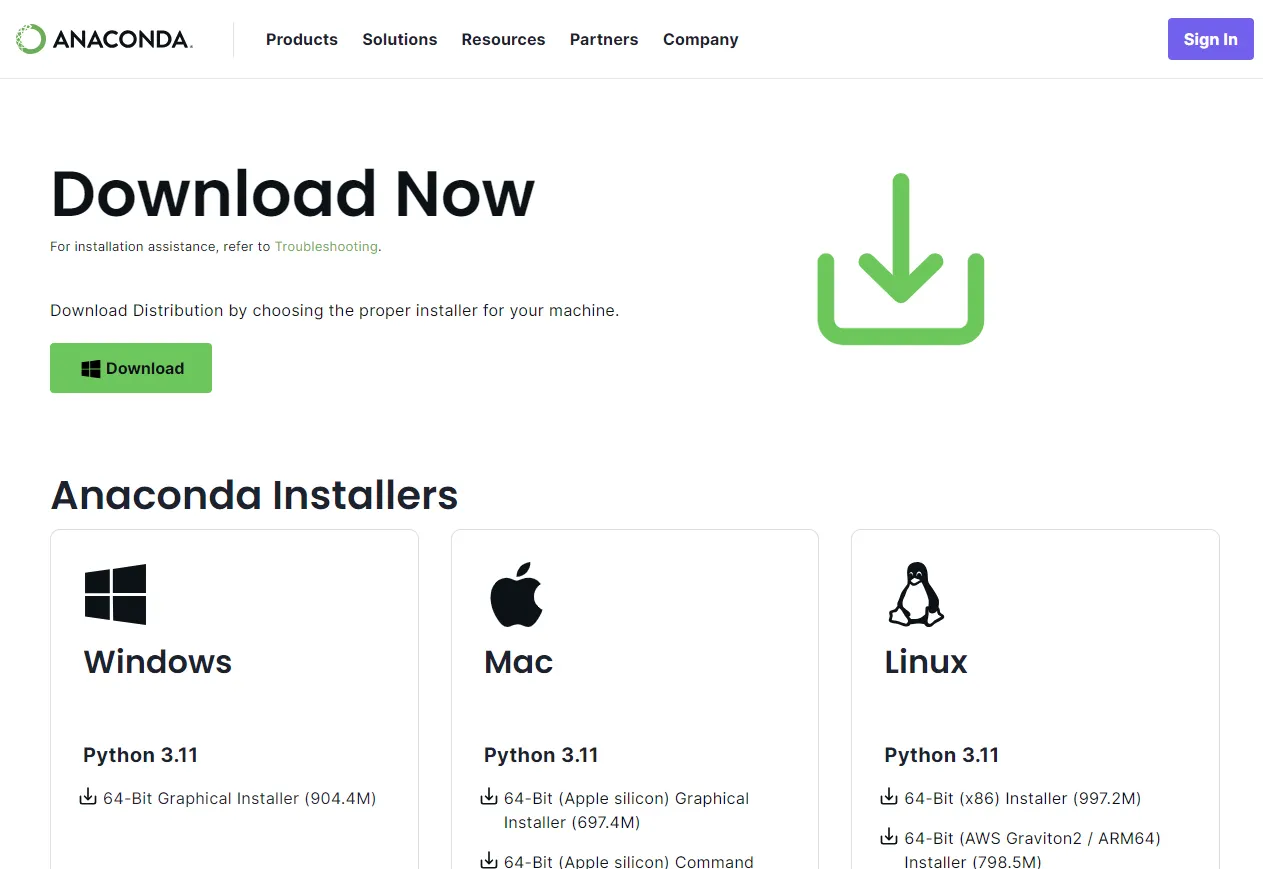
아나콘다 설치
•
Just Me 선택
•
설치 경로는 디폴트 상태 그대로 설치
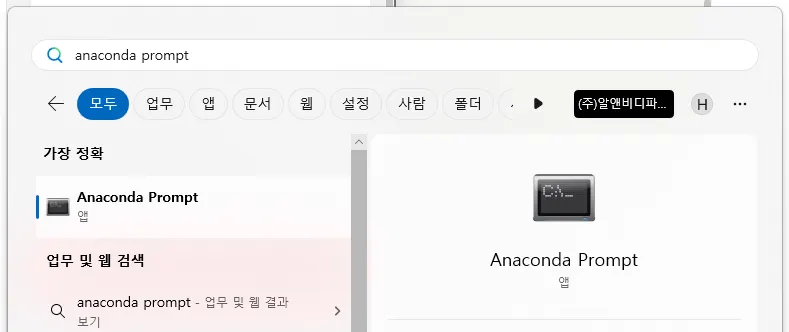
아나콘다 실행
윈도우 버튼 누르고 Anaconda prompt 검색
실행창에서 jupyter lab 입력
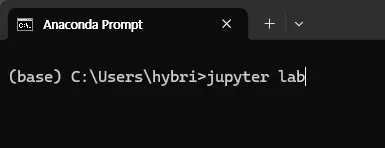
크롬 브라우저에서 주피터 랩이 실행됨
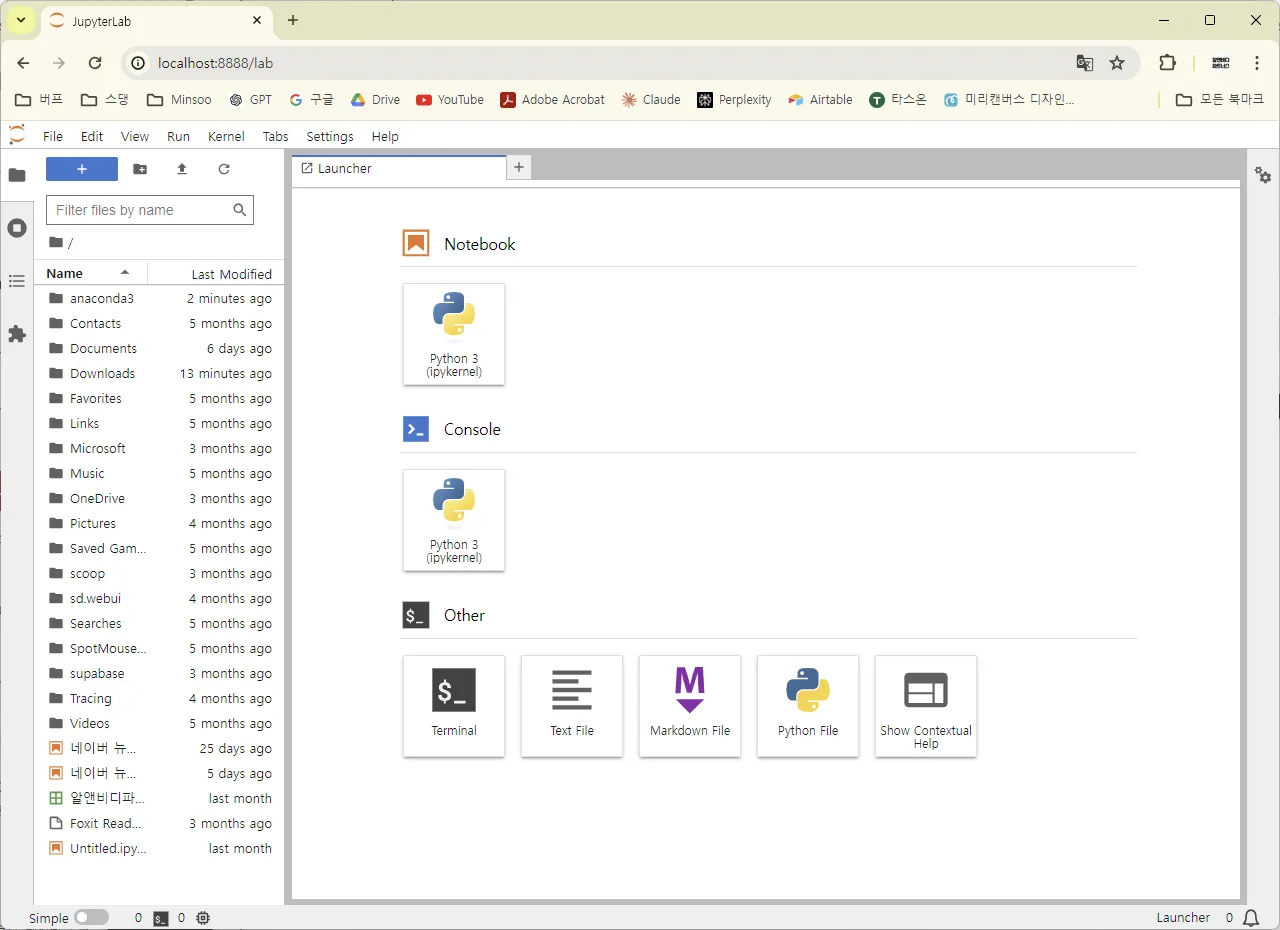
★ 주의사항 : 명령 프롬프트 창은 항상 열려있어야 함
방법#2) 주피터 노트북만 설치
파이썬 프로그램 다운로드 링크
Download Python
The official home of the Python Programming Language
https://www.python.org/downloads/
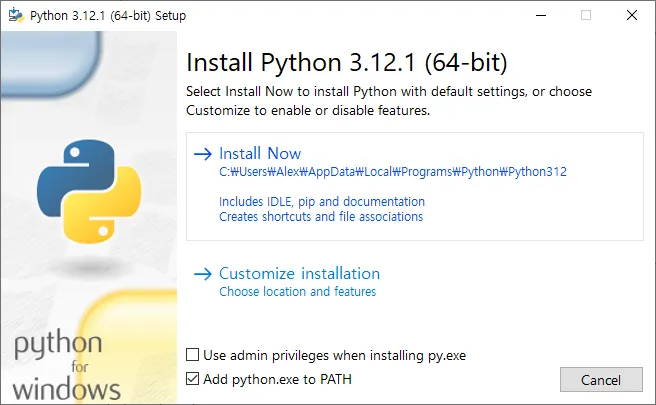
다운로드 파일 설치 > Install Now
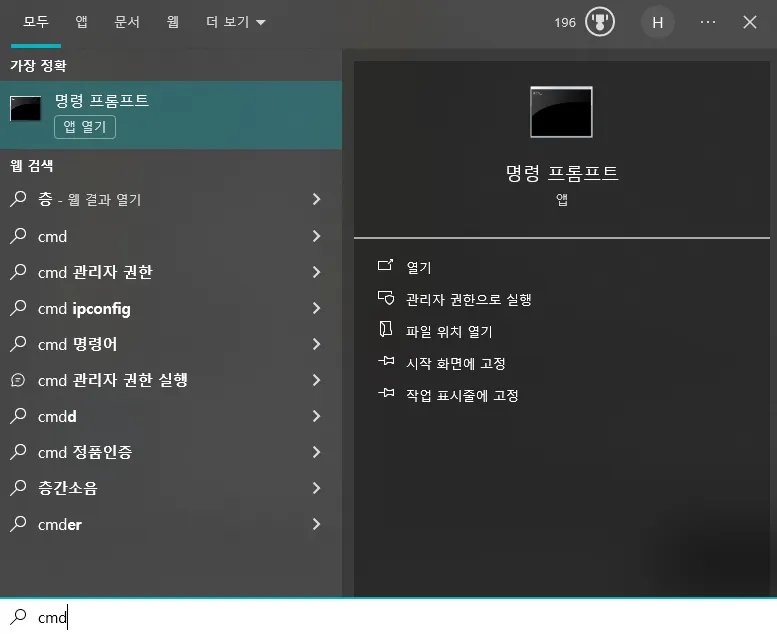
Windows > 명령 프롬프트
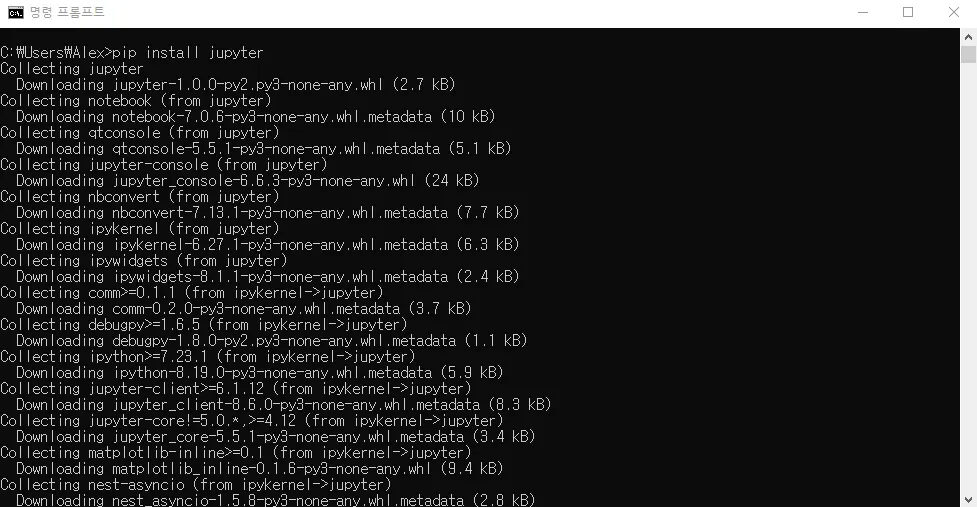
pip install jupyter
jupyter notebook 실행

준비 완료
방법#3) 구글 코랩

구글 코랩은 구글이 제공하는 구글 워크스페이스 중 하나입니다.
구글 코랩의 특징
•
클라우드 기반의 주피터 노트북 환경이다
•
설치나 설정 필요 없이, 웹 브라우저만 있으면 어디서나 사용할 수 있다
•
협업 기능: 다른 사람과 쉽게 공유하고 실시간으로 협업
•
Google Drive 통합: 데이터를 쉽게 불러오고 저장할 수 있다
파이썬 실행 환경 구축의 중요성
저도 개발자 아니고, 제가 작성할 줄 아는 코드도 거의 없습니다만,
그럼에도 불구하고 직장인이라면 전국민 모두가 PC에 이 정도 환경은 구축해야 한다고 생각합니다.
1) 코드 작성은 챗GPT에게 맡겨도 코드 실행은 내가 하자
데이터 분석 코드, 웹 크롤러 코드, 업무처리 자동화 코드 등 어려운 코딩도 챗GPT가 해줍니다.
하지만 GPT-4o를 쓰더라도 챗GPT 대화 화면에서 모든 코드를 실행하는 것은 무리가 있습니다.
챗GPT로 코드 작성을 하되 이것을 별도의 실행 환경에서 run 하는 것이 훨씬 편리합니다.
2) 코드 저장, 관리, 재실행, 재활용 편리
챗GPT 대화 화면은 코드 저장에 아주 불편합니다.
Chat history가 남기는 하지만,
예전에 만든 코드를 다시 불러와서 재실행 하는 것이 상당히 불편합니다.
챗GPT와 대화하면서 한번 수정한 코드는 이전으로 되돌리기가 너무 어렵습니다.
다시 고쳐달라고 해도 이전과는 또 다른 코드를 뱉어내는 경우가 많습니다.
잘 만들어진 코드를 재실행하고, 그걸 불러와서 또 고쳐 쓰고 하려면
챗GPT 이외에 별도의 코드 저장 공간이 있는 것이 훨씬 편합니다.
3) 독립성과 자율성
회사마다 보안정책에 따라 구글 코랩이 접속 안되는 경우도 많습니다.
하지만 아나콘다와 주피터 노트북 같은 경우는 언제 어디서나 실행이 가능합니다.
대부분의 회사에 개발자가 있기 때문에 보안 정책상 막혀있는 경우도 거의 없네요.
4) 공부
챗GPT가 데이터 분석 다 해주면 정말 편리하긴 하지만,
생성형 AI는 원래 항상 똑같은 결과를 주지는 않죠.
그래서 다음에도 동일한 데이터 분석이 잘 될지는 모를 일입니다.
하지만 챗GPT에게 코드를 받아서
내가 비록 까막눈이지만 한번 들여다 보고
챗GPT에게 친절하게 한줄한줄 다 설명해 달라고 부탁도 하고
그렇게 파악한 후에 실행을 시키고 결과를 보고,
그 과정이 아주 좋은 코딩 공부가 됩니다.
앞으로 이 환경을 이용해서 데이터 분석을 많이 해보려고 합니다.
저와 함께 공부하실 분은 이번 기회에 파이썬 실행 환경을 구축해보세요~