
_%25EB%2584%25A4%25EC%259D%25B4%25EB%25B2%2584_%25EB%2589%25B4%25EC%258A%25A4_%25EB%25B3%25B8%25EB%25AC%25B8_%25ED%2581%25AC%25EB%25A1%25A4%25EB%25A7%2581.jpg&blockId=18f88edc-d1fd-81cb-b255-ec8e2f6e3973)
GPT로 코딩하기. 네이버 뉴스 본문 크롤링하기.
지난 번에 네이버가 제공하는 네이버 뉴스 API를 이용해서 뉴스 1천건을 한꺼번에 가져왔습니다.
기술 트렌드 조사, 경쟁사 동향 조사, 내 업무 분야의 최신 뉴스 탐색을 위해 너무나 필요한 업무이지요.
하지만 한가지 아쉬움이 남았습니다.
네이버 뉴스 API는 우리에게 5가지 정보를 줍니다.
•
뉴스의 제목
•
오리지널 링크 (원본 언론사의 뉴스기사 링크)
•
링크 (네이버가 재작성한 해당 기사의 네이버 뉴스기사 링크)
•
Publication Date (해당 뉴스가 발행된 날짜)
•
Description (해당 뉴스의 내용 요약 3줄 정도)
여기에 뉴스 full text가 없습니다.
이 뉴스 기사를 읽을 것인가 말 것인가를 판단하는 정도라면 title, description 정도만 사람이 읽어봐도 충분합니다.
하지만 만약 내가 뉴스 full text마저 ChatGPT에게 주고 핵심 주제 요약, 키워드 도출, 긍정/부정 판단, 언급된 기업명 또는 기술명 추출 등의 업무까지 자동화 하고자 한다면 우리에게는 full text가 필요합니다.
하지만 이건 개발들만 할 수 있는 일이죠?
크몽에서 검색해보면 프리랜서분들이 아주 활발하게 활동하고 계시는 분야입니다.

혹시나 GPT가 잘 할지도 모르고, 코딩 모르는 나도 어쩌면 GPT의 도움으로 이걸 혼자서 성공할지도 모르니 일단 도전을 해보겠습니다.
GPT와 함께 네이버 뉴스 본문 크롤링하기
GPT에게 나의 계획을 설명한다
GPT와 함께 작업하기 위해 나의 목표를 설명합니다.

구글 코랩에서 실행할거라고 설명합니다. 그러면 아마도 코랩에서 실행되는 파이썬으로 코드를 짜 주겠죠.
크롤러를 위해 어떤 라이브러리가 좋을지도 질문해봅니다.
이름을 들어본 적이 있는 Beautiful Soup로 하기로 마음 먹었습니다. 네이버에서 크롤러 검색해보니 이걸로 구현했다는 글들이 많더라구요. 그래서 그냥 이걸로 골랐습니다.
한마디 더 했더니 바로 코딩에 착수하네요.
설마 이거 한번에 돌아갈까요?
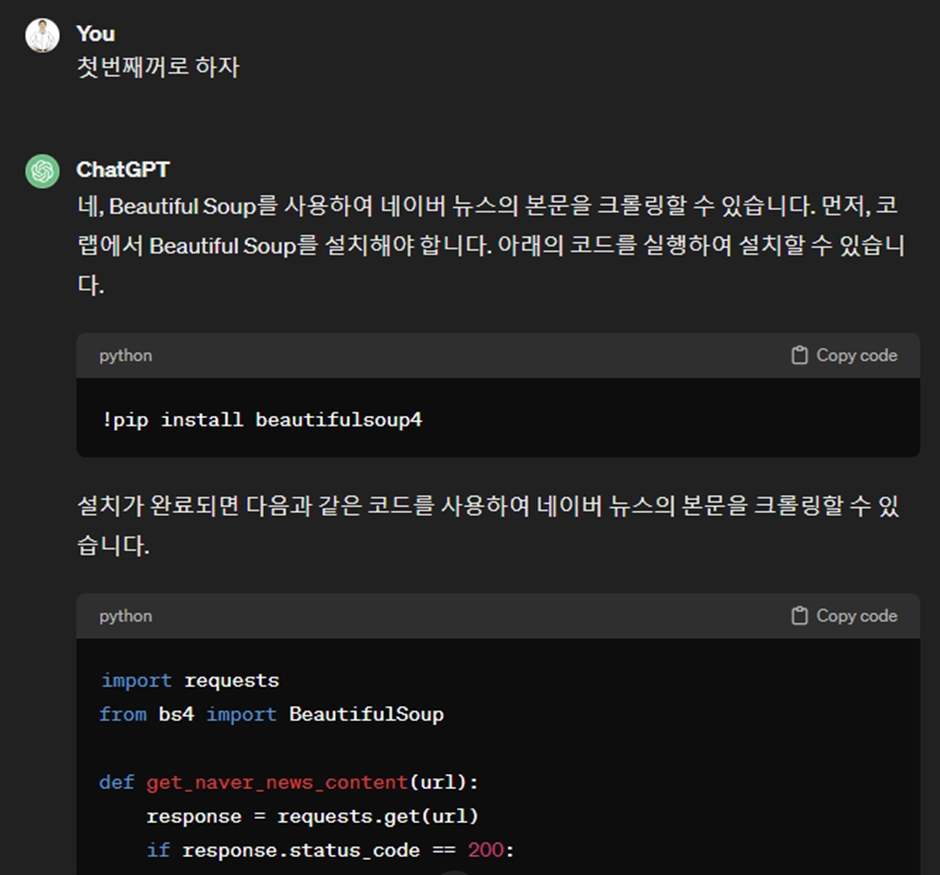
일단 구글 코랩으로 가서 복붙 합니다.
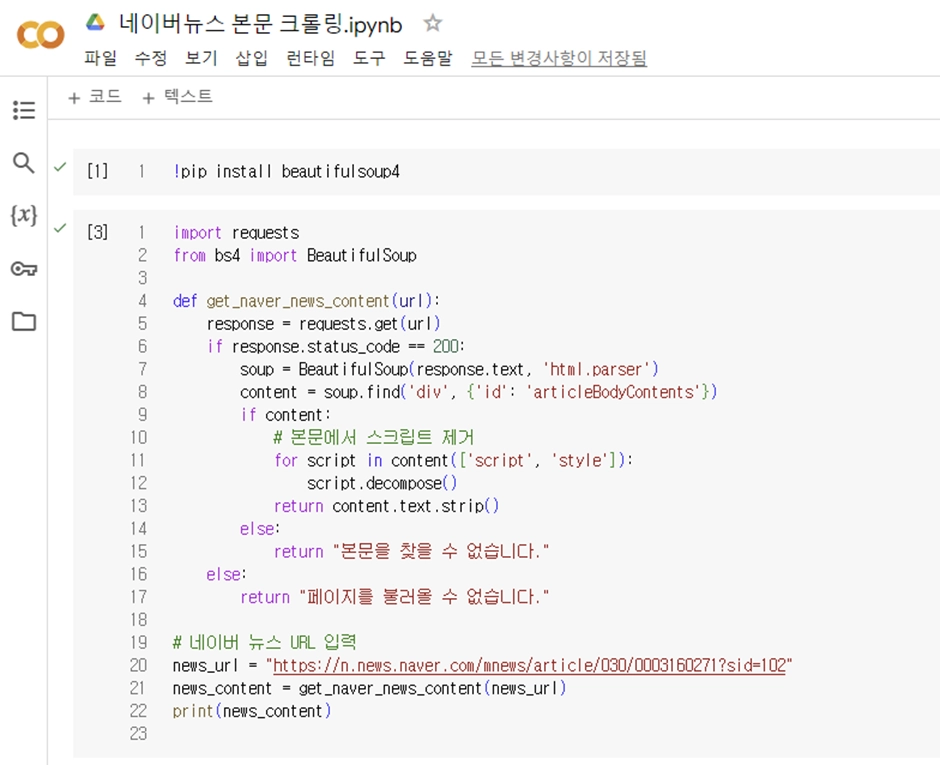
[1]번 먼저 실행해서 beautifulsoup4를 설치합니다.
그리고 [3]번 코드를 실행합니다.
설마 한번에 성공하나요?
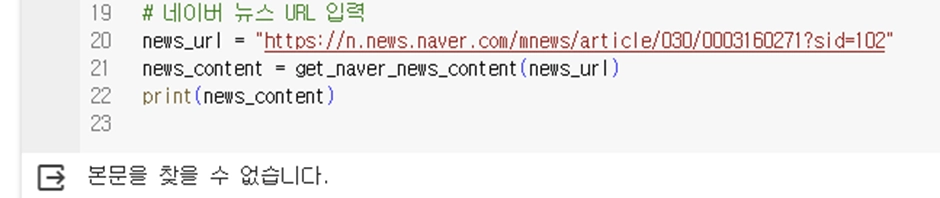
네~ 안 되네요.
본문을 찾을 수 없다고 합니다. ㅠㅜ
늘 하던대로 GPT에게 투덜거리러 갑니다.

아~ 본문이 <div>에 들어있을거고 그 id가 아마 articleBodyContents일거라고 합니다. 다만, 그게 다를수도 있으니 찾아보라 하네요. 그걸 알려주면 자기가 도와준다네요.

모르는 건 항상 GPT에게 일단 물어보는 습관이 몸에 붙었습니다.
HTML 구조를 알아보려면 크롬에서는 개발자 도구를 열어보라고 단축키도 알려주고, 각 요소를 클릭해서 HTML 코드를 살펴보라 하네요.
크롬 브라우저에서 해당 네이버 뉴스 기사를 열고 개발자 도구를 열어봅니다.
GPT가 알려준대로 ctrl + shift + I 를 눌러도 되고 펑션키 F12를 눌러도 됩니다.
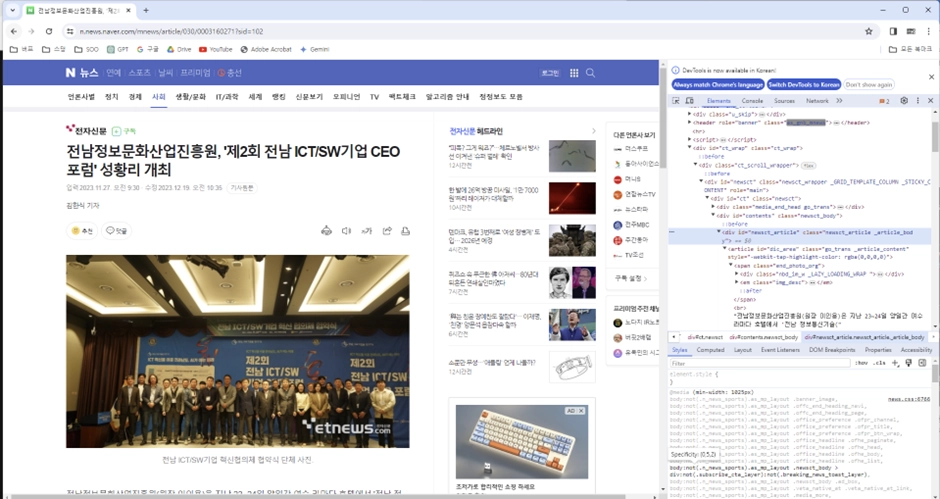
‘검사’ 버튼 누르고 네이버 뉴스 본문에서 여기저기 찍어봅니다.
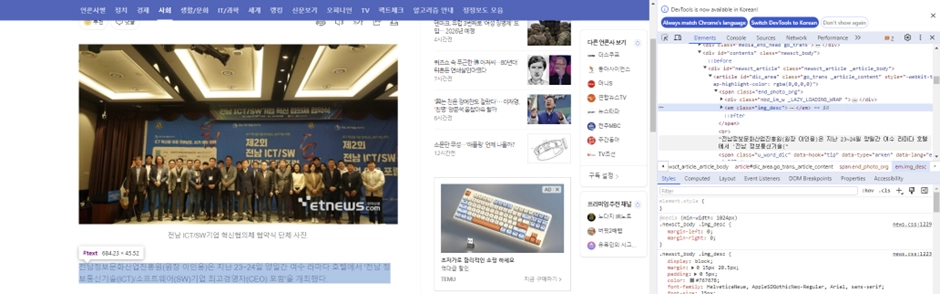
사진 바로 밑에서 본문이 시작하는 것 같아서 그 근처를 찍어보다보니, “전남정보문화산업진흥원(원장 이인용)은 지난~~~” 이렇게 본문이 시작하는 text가 보입니다.
이 근처에 본문의 id가 있을 것 같습니다.
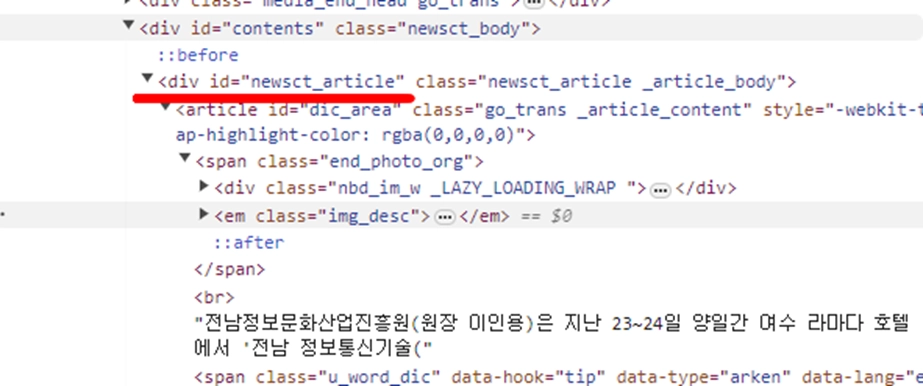
찾았군요. <div id=”newsct_article” class~~~> 이렇게 나오네요.
Newsct_article이 본문의 id인 것 같습니다.
찾았으니 이제 GPT에게 고자질하러 가자구요.
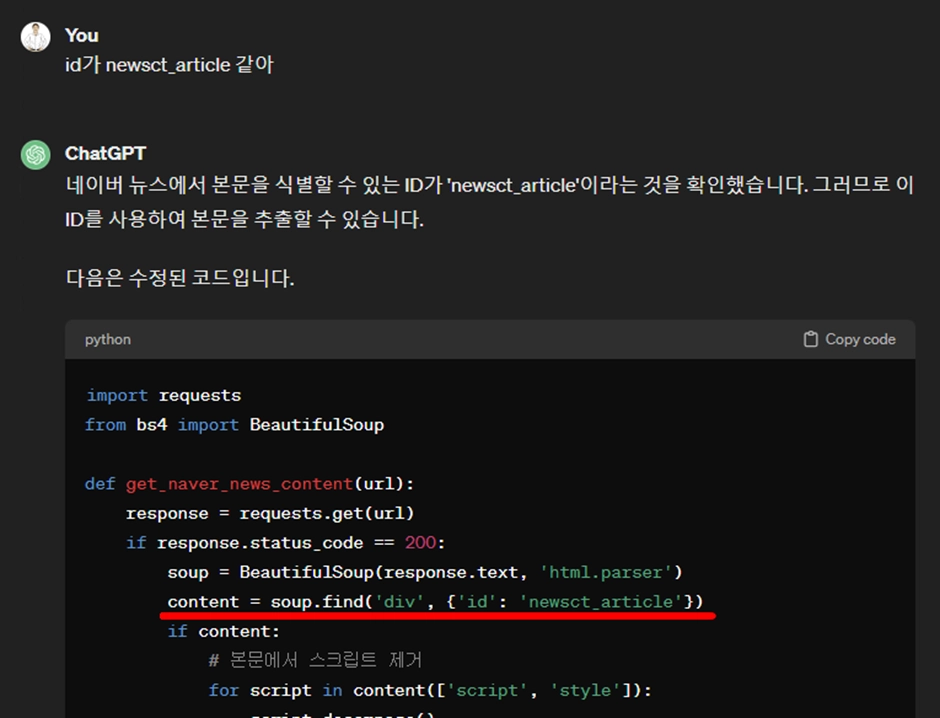
GPT에게 알려줬더니 이 부분의 코드를 수정해줬네요.
그럼 이제 코랩에서 2차 시도를 해보겠습니다.
이번에는 성공하면 좋겠네요.
물론 실패해도 됩니다. 또 GPT에게 오류를 알려주고 같이 고치면 되죠.
이러면서 점점 코딩에 대한 이해도도 높아지고 좋잖아요 ^^
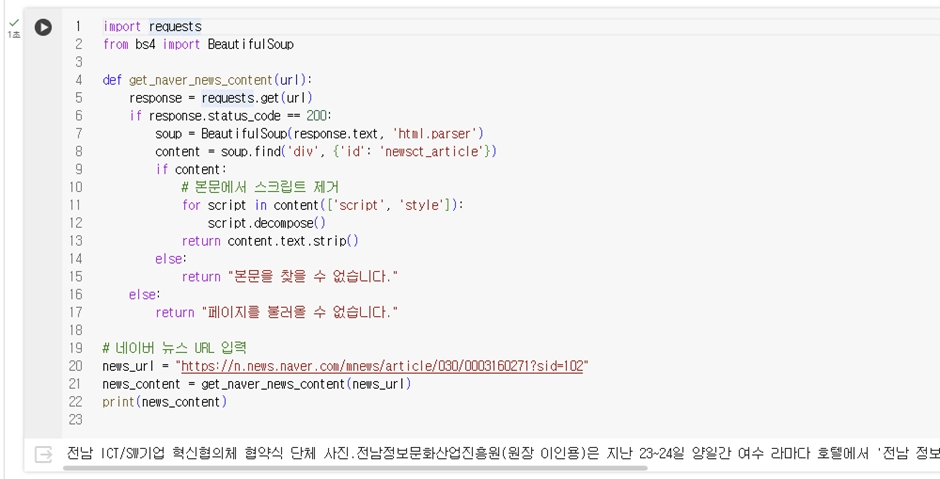
와우~ 2차 시도에 성공했군요.
출력으로 아주 긴 text가 나옵니다.
복사해서 메모장에 넣고 원래 뉴스 기사와 비교해보니 full text 맞습니다.
앗싸~
<구글 코랩에서 크롤링한 뉴스 기사>
전남정보문화산업진흥원(원장 이인용)은 지난 23~24일 양일간 여수 라마다 호텔에서 '전남 정보통신기술(ICT)/소프트웨어(SW)기업 최고경영자(CEO) 포럼'을 개최했다.이번 포럼은 기업 간 네트워킹 기회를 제공하고 미래 전략을 논의하기 위해 '전라남도, 인공지능(AI)이가 여는 시대'를 주제로 진흥원과 전남 소재 ICT/SW 기업 임원진, 유관기관 관계자 등 40여명이 참석했다.첫째 날에는 심춘보 순천대 SW중심대학사업단장의 '챗GPT와 생성형 AI 모델의 현황 및 발전방향'에 대한 기조연설을 시작으로 안현수 알앤비디파트너스 컨설턴트의 'AI 시대의 기회'에 대한 강연이 이뤄졌다. 한국인터넷진흥원 등 5개 공공기관의 'ICT관련 공공기관과 지역기업 협력방안'에 대한 강연과 손환희 강사의 'AI 시대, 리더십' 등 다양한 프로그램을 마련했다.둘째 날인 24일에는 조정란 JR금융경영연구소 대표의 '기업의 정책자금 운용'에 대한 강의, 배경율 정보통신정책연구원장의 '대외 환경변화와 ICT 전망'을 주제로 특별 초청강연을 진행했다. 이어 '전남 ICT/SW기업 혁신협의체' 추가 구성 협약식으로 포럼을 마무리했다.이번 포럼은 그간 교류 기회가 없었던 전남 ICT기업 간의 네트워킹의 장이 정례화됐다는 점에서 참가자들의 좋은 반응을 이끌어 냈다.이인용 원장은 “이번 포럼이 전남 ICT기업 간 파트너십을 구축하고 기업을 중심으로 전남 ICT산업의 미래를 고민하는 자리가 되었기를 바란다”며 “진흥원은 전남 ICT/SW기업 CEO 포럼이 전남을 대표하는 브랜드로 성장할 수 있도록 지원을 아끼지 않겠다”고 말했다.
<네이버 뉴스 사이트에 있는 뉴스 기사>

한번 만들어뒀으니 이제 네이버 뉴스기사 본문은 언제든지 가져올 수 있게 되었습니다.
이게 자동화 하는 재미죠 ^^
단, 몇가지 유의사항이 있습니다.
•
네이버 뉴스에서 div id를 바꿀 수도 있습니다. 그럼 이 코드는 오류가 납니다. 하지만 이런 일이 자주 생기지는 않죠. 다행입니다.
•
news.naver.com 도메인에 들어있는 “네이버가 재생산한 뉴스”만 가능합니다. 한국경제신문, 전자신문 등 미디어마다 HTML 구조가 다르기 때문에 하나의 코드로 모든 뉴스를 다 가져올 수 있는 것이 아닙니다.
•
특정 미디어의 뉴스가 필요하다면 그 사이트를 분석해서 본문 id를 찾아보세요
•
뉴스를 포함한 웹 크롤링 자체가 불법은 아니지만 윤리적인 측면을 고려하시기 바랍니다. 뉴스기사는 해당 언론사의 창작물이므로 재가공을 통한 상업적 이용은 하면 안되겠습니다. 또한 이름, 생년월일, 이메일주소, 전화번호 같은 개인정보는 특히 신중하게 판단하시기 바랍니다.
이 코드는 한번에 하나의 url에서만 본문을 크롤링 합니다만, 우리는 GPT와 함께 이를 응용할 수 있습니다. 본문을 가져올 url 주소를 코드에 삽입하는 것이 아니라, 변수로 처리를 하고 csv 파일 형태로 url list를 입력받도록 수정하면 되겠죠. 그리고 그 list대로 각각 들어가서 본문을 받아오면 되겠죠.
지난 시간 동안 공부한 내용들을 종합해 보자면,
1) 네이버 뉴스 API를 이용해서 1천개씩 뉴스를 가져온다
2) csv 파일로 저장한다
3) list 중에서 link 부분에news.naver.com 도메인인 list만 추출한다
4) 추출된 list대로 접속하여 뉴스 본문도 모두 가져와서 파일에 update 한다
5) 최종 파일을 구글시트에 저장한다
6) 구글시트에 ChatGPT를 연동시켜서 각 뉴스의 본문에 대해 필요한 분석/요약/정리/판단/비교/추출 등 작업을 자동화한다
7) 작업결과를 업무에 활용한다.
자~ 어떤가요?
이 모든 것들이 지금까지 우리가 다 함께 공부했던 것들이죠?
각각을 따라해보고 연습하신 분들이라면,
오늘 이 긴 흐름의 업무자동화도 충분히 하실 수 있습니다.
하다가 안 되면, GPT한테 물어보세요~~~
GPT만큼 똑똑하진 못하지만 저한테 물어보셔도 됩니다 ^^